その時点でGoogleは、検索結果ページの上位に表示させるものを判断するために、リアルタイムコンテンツソースの関連性の評価を開始する。ここでは3つのことが重要になる。1つめはコンテンツの質だ。つまり、コンテンツがスパムか本物かを区別する。2つめは、コンテンツの作者の信頼性という点だ。フォロワーの数だけでなくフォロワーの質まで評価するために、「PageRank」に似たアルゴリズムを使って判定する。3つめはセマンティック評価だ。これは、Googleの言語データを使用して、同じ文字が使われていても無関係のステータス更新を除外するものだ。例えば、「gm cars(General Motors製自動車)」と「gm foods(遺伝子組み換え食品)」を区別する。
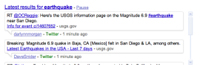 先日サンディエゴとメキシコ北部を襲ったマグニチュード7.2の地震によって、Googleのリアルタイム検索ボックスが表示された。
先日サンディエゴとメキシコ北部を襲ったマグニチュード7.2の地震によって、Googleのリアルタイム検索ボックスが表示された。この段階では厳密な意味での科学とはいえない。ニュース速報が出るようなイベントの最中にリアルタイム検索結果ストリームを見た人は、フォロワーが10人しかいないようなTwitterユーザーの無関係なツイートをたくさん目にするだろう。また、あるブログ投稿を流用したブログ投稿を、さらに流用したブログ投稿が多数表示されるはずだ。
米Yahooの検索担当シニアバイスプレジデントShashi Seth氏は、次のように語る。「リアルタイムで入ってくる情報について、リアルタイムでない情報の場合と同じような関連性チェックとランキングを行うチャンスはない」
リアルタイム検索ビジネスに携わる人は誰でも、大いに苦労しながら、リアルタイム世界の管理の一環として、多岐にわたる情報ソースを検討する。だが前述のように、結局話題になっているのはTwitterだ。
Sullivan氏は「Twitterは、Googleに多額のコンテンツ対価を支払わせることに成功した数少ない会社の1つという意味で、驚くべき快挙だ」と言う。Googleは通常、Associated Pressなどとのいくつかの契約を除いて、コンテンツに対価を支払うことには消極的だが、Twitterの「firehose」にアクセスする権利を得るために、数百万ドルと言われる金額を進んで差し出した。Business Weekは2009年12月、TwitterがGoogleおよびMicrosoftとの契約から2500万ドルとも言われる対価(正確な金額は確認されていない)を得たと報じた。
なぜそれほどの資金を投じるのだろうか。それはひとえに、従来型の検索エンジンがウェブをクロールする方法でTwitterをクロールするのがあまりにも難しいからだ。現時点で主要検索エンジン3社すべてが、Twitterにコンテンツを直接プッシュさせる契約に署名しており、この3社(そしてTwitter)が時間、労力、資金を節約できるようにしている。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 無限に広がる可能性
無限に広がる可能性
すべての業務を革新する
NPUを搭載したレノボAIパソコンの実力
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は  絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法
絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法  なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは