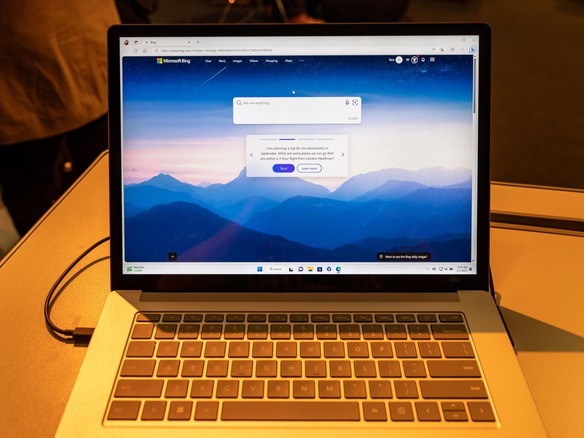
「Bing」の人工知能(AI)で強化された検索結果をよく見ると、このウェブサイトが、使用している「ChatGPT」の技術基盤と、競合するGoogleの「Bard」で明らかになっているものと同じ種類の間違いを起こす場合があることが分かる。
限定プレビュー公開されているBingの新しいバージョンには、OpenAIの大規模言語モデル(LLM)技術が採用されている。OpenAIは、Microsoftが出資する研究組織で、AIチャットボットChatGPTで一躍IT業界でのスポットライトを浴びた。インターネット上の非常に広範なデータでトレーニングされたChatGPTとその関連技術は、目を見張る結果を生成できるが、実際に事実を知っているわけではなく、間違いを起こす場合がある。
Bingは、Microsoftの検索技術によって結果の「裏付け」を行い、元の文書の正確性と信頼性を評価し、出典元へのリンクを提供して、ユーザーが自分で結果をより適切に評価できるようにすることで、そのような間違いを回避しようとしている。しかし、AIと検索エンジンの研究者であるDmitri Brereton氏やその他のユーザーは、Bingのデモに間違いを発見している。例えば、Gapの四半期決算報告書に関する誤った財務データなどだ。
それは、AIに対する高まる期待に水を差すものだ。AIは、確かに卓越した有用な結果を生成できるが、問題は、それができていない場合を見極めることである。検索エンジン業界は、正しい方法を見出そうと努めているので、それに伴って、より注意深い結果が生成されるようになるだろう。
Googleは、米国時間2月6日に公開したBardのデモ回答の中に、ジェームズ・ウェッブ宇宙望遠鏡に関する誤った情報があり、非難された。Bardはまだ、一般公開はされていない。
Microsoftは14日、Googleが自社の誤りについて述べた内容と同じような回答を示した。「まだやらなければならない作業があることを認識しており、このシステムはこのプレビュー期間中に間違いを起こす可能性があると予想している。フィードバックが不可欠なのはそのためであり、それによってわれわれは学習し、モデルを改良できる」(Microsoft)
1つの問題は、大規模言語モデルが、ある程度の精査を通過した学術論文やWikipediaの記事などのテキストを使用してトレーニングされているとしても、その材料から事実に基づく回答を組み立てるとは限らないことにある。
インターネットのパイオニアでGoogleの研究者であるVint Cerf氏は13日、AIは「サラダシューターのようなもの」で、事実をキッチンいっぱいにまき散らすが、自分が何を生成しているのかを実際には理解していないと述べた。「私たちが望む自己認識の状態には、ほど遠い」と、同氏は「Tech Surge Global Deep Tech Summit 2023」の場で述べた。
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 ビジネスの推進には必須!
ビジネスの推進には必須!
ZDNET×マイクロソフトが贈る特別企画
今、必要な戦略的セキュリティとガバナンス
 CES2024で示した未来
CES2024で示した未来
ものづくりの革新と社会課題の解決
ニコンが描く「人と機械が共創する社会」

 近い将来「キャッシュレスがベース」に--インフキュリオン社長らが語る「現金大国」に押し寄せる変化
近い将来「キャッシュレスがベース」に--インフキュリオン社長らが語る「現金大国」に押し寄せる変化
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する
 「当たり前の作業を見直す」ことでパレット管理を効率化--TOTOとユーピーアールが物流2024年問題に挑む
「当たり前の作業を見直す」ことでパレット管理を効率化--TOTOとユーピーアールが物流2024年問題に挑む
 ハウスコム田村社長に聞く--「ひと昔前よりはいい」ではだめ、風通しの良い職場が顧客満足度を高める
ハウスコム田村社長に聞く--「ひと昔前よりはいい」ではだめ、風通しの良い職場が顧客満足度を高める
 「Twitch」ダン・クランシーCEOに聞く--演劇専攻やGoogle在籍で得たもの、VTuberの存在感や日本市場の展望
「Twitch」ダン・クランシーCEOに聞く--演劇専攻やGoogle在籍で得たもの、VTuberの存在感や日本市場の展望

 気候変動対策に挑む注目のクリーンテック企業【アグリ、フードテック、素材、循環資源編】
気候変動対策に挑む注目のクリーンテック企業【アグリ、フードテック、素材、循環資源編】  OpenAIの検索エンジン「SearchGPT」、グーグル検索と違う5つのこと
OpenAIの検索エンジン「SearchGPT」、グーグル検索と違う5つのこと  「スマートリング時代」の到来を予感させる3つの理由
「スマートリング時代」の到来を予感させる3つの理由