
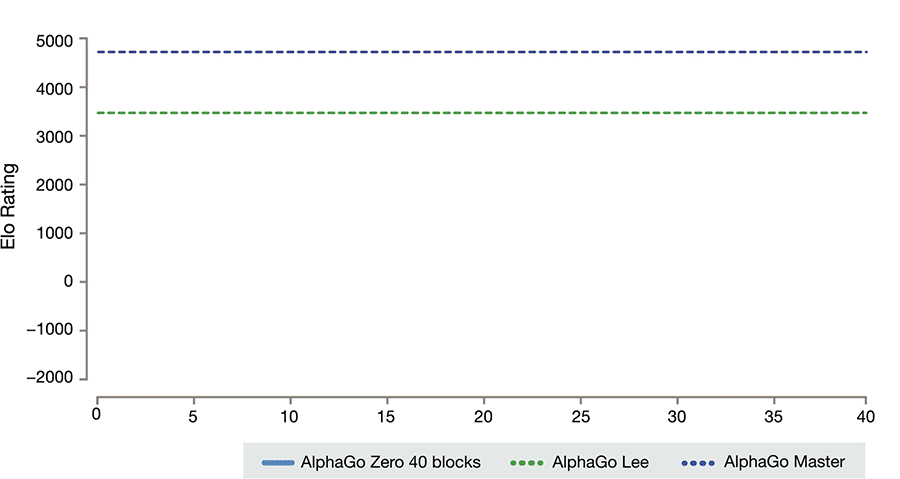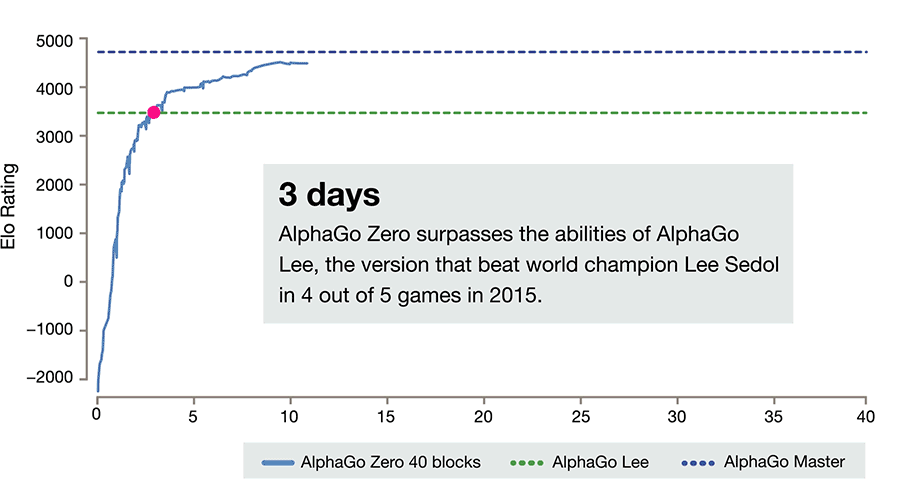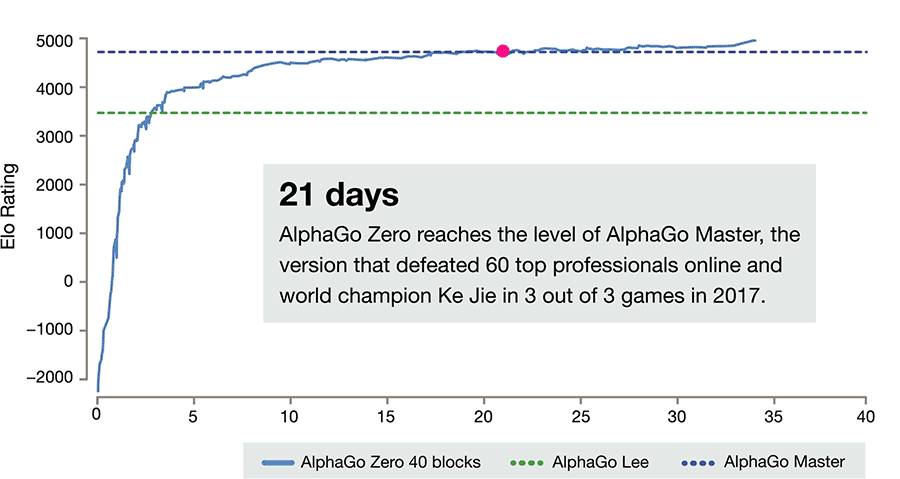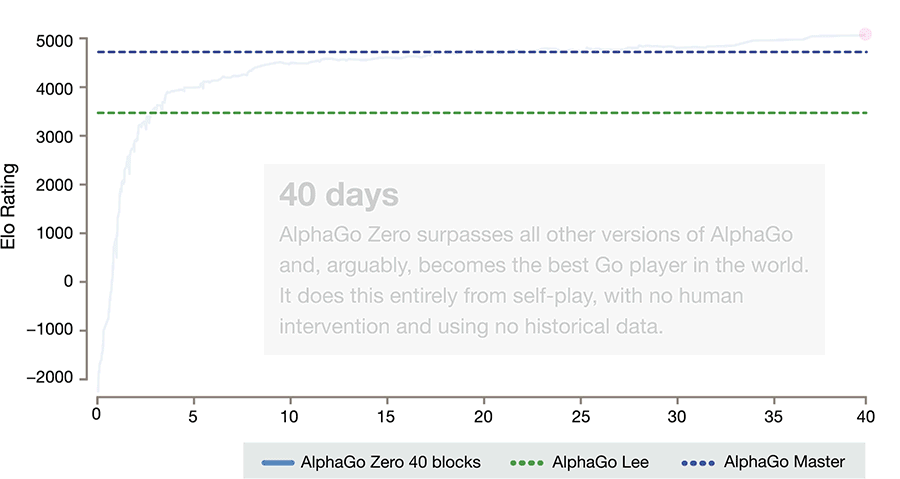
Google傘下のDeepMindは米国時間10月18日、囲碁AI「AlphaGo」をさらに進化させた「AlphaGo Zero」を発表した。新たな学習方法により短時間で進化し、わずか3日間の学習で100対0という圧倒的な差で従来のAlphaGoを破るに至ったという。
AlphaGoは2016年、トップ棋士の1人である李世ドル氏に勝利したことで話題となり、2017年5月には「世界最強」とされる中国の囲碁棋士、柯潔氏に3連勝した後、囲碁対局から引退していた。AlphaGoはその後も進化しており、さらに強力となった「Master」バージョンが存在しているが、AlphaGo Zeroは40日後にこのバージョンも追い抜いたという。
 提供:DeepMind
提供:DeepMind
DeepMindによると、従来のAlphaGoは、まずアマチュアやプロの棋士による何千もの対局を基に訓練され、囲碁の打ち方を学習する。AlphaGo Zeroはこの手順を飛ばして、自分自身との対局のみで学習するという。最初の段階では完全に行き当たりばったりの対局となるが、この学習方法により、短時間で人間の棋士やAlphaGoを凌駕することが可能になった。
自らが自らの教師になるという斬新な強化学習方法により、これを実現できたとDeepMindは述べている。同社によると、このシステムは、囲碁について何も知らないニューラルネットワークから始まり、その後、強力な検索アルゴリズムと組み合わせることで、自分自身と対局する。対局を通して調整やアップデートを重ね、相手の打つ手、さらに対局の最終的な勝者も予測できるようになるという。
人間の知識の限界によって抑制されないという点で、この手法はAlphaGoの手法より強力だとDeepMindは述べている。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 プライバシーを守って空間を変える
プライバシーを守って空間を変える
ドコモビジネス×海外発スタートアップ
共創で生まれた“使える”人流解析とは
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は .jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話  「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた