楽天グループは12月18日、日本語に最適化した大規模言語モデル(LLM)「Rakuten AI 2.0」、および小規模言語モデル(SLM)「Rakuten AI 2.0 mini」を発表した。来春を目途にオープンソースとして公開するという。
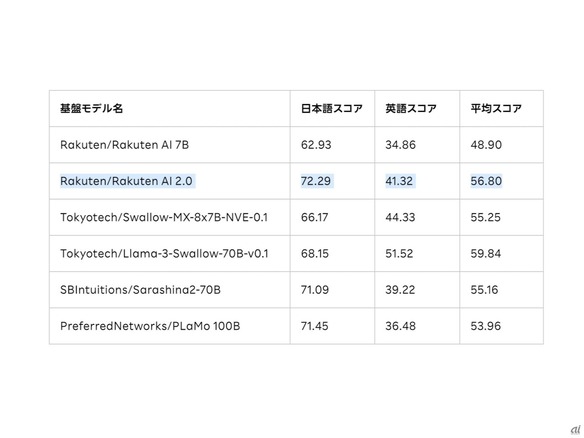
 Rakuten AI 2.0と他のモデルの比較
Rakuten AI 2.0と他のモデルの比較
「Rakuten AI 2.0」は、Mixture of Experts(MoE)アーキテクチャを採用した8x7B(8つの70億パラメータモデル)構成のモデルだ。入力トークンは最適な2つの「エキスパート」(サブモデル)へと振り分けられ、効率的な動作を実現する。楽天によれば、この設計により8倍規模の高密度モデルに匹敵する性能を示しながら、計算資源の使用を約4分の1に抑えられるという。
また、日本語性能はRakuten AI 7Bと比較して、8つのタスクで62.93から72.29へと約15%向上し、自然言語処理タスクにおいて高い精度を実現したとしている。
一方、「Rakuten AI 2.0 mini」は15億パラメータで構成される小規模モデルで、モバイル端末への導入を可能にし、データのローカル処理を実現する。これにより、プライバシー保護や低遅延が求められる特定のアプリケーションに最適なモデルとなる。
楽天グループでChief AI & Data Officerを務めるティン・ツァイ氏は、「今回開発した日本語に最適化したLLMと楽天初となるSLMは、高品質な日本語データや革新的なアルゴリズム、エンジニアリングにより、従来以上に効率性が高いモデルだ。日本の企業や技術者などの専門家がユーザーに役立つAIアプリケーションを開発することを支援するための、継続的な取り組みにおける重要な節目になる」とコメントした。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ
 無限に広がる可能性
無限に広がる可能性
すべての業務を革新する
NPUを搭載したレノボAIパソコンの実力

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は  なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは  絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法
絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法