人工知能(AI)プログラムのトレーニングに関する年2回のベンチマークテストで、GoogleとNVIDIAがトップの座を分け合ったことが、MLCommonsが米国時間6月29日に発表したデータで明らかになった。MLCommonsは、機械学習のパフォーマンス測定で人気のテスト「MLPerf」を統括する業界コンソーシアムだ。
MLPerfのバージョン2.0ラウンドのトレーニング結果によると、市販されているシステム向けの4つのタスク、具体的には画像認識、物体検出(2種類)、およびBERT自然言語処理モデルで、Googleはニューラルネットワークのトレーニングにかかる時間が最も短く、最高スコアをマークした。
一方、NVIDIAは8つあるタスクのうち、残りの4つのタスクでトップに輝いている。こちらは画像セグメンテーション、音声認識、レコメンデーションシステム、および「MiniGo」データセットで碁を打つための強化学習だ。
両社とも複数のベンチマークテストで高いスコアを獲得したが、Googleが市販システム向けのテスト結果を報告したのは、トップスコアを獲得した4つのタスクのみで、他の4つのタスクについては報告していない。これに対して、NVIDIAはすべてのタスクのテスト結果を報告している。
このベンチマークテストは、ニューラルネットワークの「重み」、つまりパラメーターを調整して、コンピュータープログラムが所定のタスクで基準となる精度を達成するまでの時間を分単位で報告するものだ。この一連のプロセスは、ニューラルネットワークの「トレーニング」と呼ばれている。
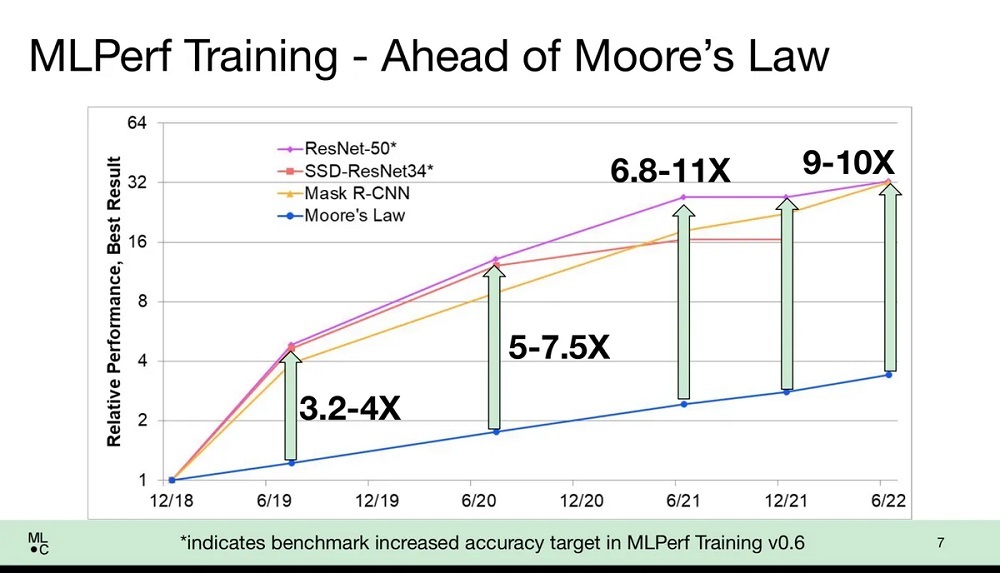
処理能力の向上とソフトウェアによるアプローチの高度化のおかげで、すべてのベンダーでトレーニング時間の大幅な短縮が認められた。MLCommonsのエグゼクティブディレクターを務めるDavid Kanter氏は、大まかに言えば、トレーニングに関してはムーアの法則を上回る勢いでパフォーマンスが向上していると、メディア向けの会見で説明した。ムーアの法則とは、チップに搭載可能なトランジスタの数が1年半ないし2年ごとに倍増し、それに伴ってコンピューターの性能が向上するというよく知られた経験則だ。
例えば、数百万件の画像に分類ラベルを割り当てるトレーニングをニューラルネットワークに対して行った場合、昔から使われてきたImageNetタスクのスコアは、チップの能力向上のみを考慮した場合よりもパフォーマンスの向上が著しく、9~10倍に達していると、Kanter氏は述べている。
「われわれはムーアの法則よりもはるかに優れた成果をあげている。トランジスタとパフォーマンスに直線的な関係があるとすれば、パフォーマンスの向上は3.5倍程度にとどまるはずだが、実際に得られている成果はムーアの法則の10倍の速度だ」と、Kanter氏は語った。
この性能向上の恩恵は搭載されているチップがわずか8つの「1台のワークステーションを使っている研究者」も含め、「ごく普通の人たち」にももたらされると、Kanter氏は述べた。
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 無限に広がる可能性
無限に広がる可能性
すべての業務を革新する
NPUを搭載したレノボAIパソコンの実力
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は  「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた .jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話