2月27〜28日の2日間に渡って開催されたイベント「CNET Japan Live 2018 -AI時代の新ビジネスコミュニケーション-」。2日目には、AIやロボット関連ベンチャー2社のCEOによる対談が行われた。テーマは「ロボット&モビリティとのコミュニケーション」。人間が音声やジェスチャーで機械的システムとコミュニケーションする際の課題について、ざっくばらんに語り合った。

登壇したのは、Nextremer代表取締役CEOの向井永浩氏、ユカイ工学CEOの青木俊介氏。モデレーターはCNET Japan副編集長の藤井涼が務めた。
向井氏がCEOを務めるNextremerは2012年10月創業。以来、AI活用型の対話システム開発を一貫して行っている。現在は、さまざまな分野での応用を想定したマルチモーダル対話システム「minarai(ミナライ)」を展開。チャットボットや対話型デジタルサイネージのバックエンドとして広く利用されているという。

そのminaraiのもう1つの注力分野がモビリティ(車)だ。2017年11月から2018年2月末まで本田技研工業(ホンダ)と共同で、レンタカー向け観光ガイドシステム「ラジオDJ」の実証実験を沖縄で実施した。音声入力による周辺情報の検索はもちろん、複数のAIキャラクター同士のかけあい対話に人間が“割り込める”機能を備える。
ユカイ工学は2007年12月に設立され、コンシューマー向けのロボット製品を数多く世に送り出している。2012年4月発売の「Necomimi」は、その名の通り猫の耳のような形状だが、脳波センサを内蔵。集中度・リラックス度に応じて耳が立ったり、逆に垂れ下がるといった仕掛けが盛り込まれている。
そして2018年秋には「Qoobo(クーボ)」を発売予定。丸々としたクッションに“尻尾”がついていて、なで方に応じて尻尾の動きが変化するというセラピーロボットだ。「コミュニケーションのおける『言語』の割合は4割程度と言われる。実際にはイントネーション、ジェスチャーなどが関わっているが、現在は言語を音声処理してテキストに変換するのが主体で、捨てられてしまっている情報も多い。そういった部分をロボットのジェスチャーで再現できるのではないか、という発想からQooboのプロジェクトが立ち上がった」(青木氏)。
AIやロボットの進化が進む一方、人とデバイスを結ぶインターフェースについてはまだまだ課題も多い。たとえばデジタルサイネージは、単純に画像を表示するタイプもあれば、タッチパネルで操作ができるタイプもある。しかし、ユーザーは一見しただけではどちらのタイプか分かりづらい。結果、せっかくの機能が持ち腐れになるケースもある。今後は音声対話が可能なデジタルサイネージも増えると見込まれるが、そこでどのようなインターフェースを構築するかは、デバイスの利用率をも左右しかねない。
向井氏がその解決案として挙げたのが、音声対話型サイネージの前にメガホンを置くことだった。非常にアナログな手法ながらメガホンを見れば人は「なにか声を出せばよい」という発想が自然に生まれる。この手法はテレビ朝日でのイベントで実際に試されたが、向井氏は「1つのイノベーションだった」と回想し、その効果の高さをうかがわせた。
また、自然言語での音声対話システムは、その利用場所がプライベート空間かパブリック空間かによっても前提条件が変わる。たとえばGoogle Homeのようなシステムは、操作に必要な音声コマンドを利用者側がある程度記憶しておかねばならない。これは自宅などのプライベート空間であればそれほど問題にならないが、パブリック空間となると、コマンド一覧表を貼り出すといった工夫が必要になる。
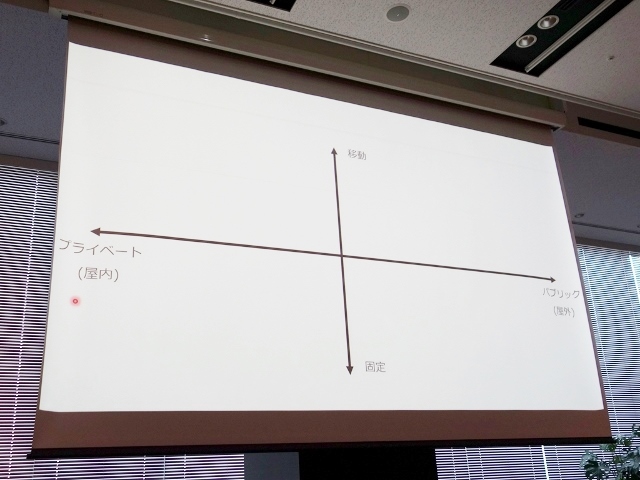
よって、音声対話システムを構築する上では、「パブリックとプライベート」という軸に「移動と固定」を加えることで、考慮すべきポイントが浮かび上がってくる。「たとえば、自分で運転中の車内は、そもそもジェスチャーなどができないため、音声入力との相性が良いと考えられている。また、車内で歌ったりする人がもともと多いので、(前述の)沖縄の実証実験でも利用者の方はかなりよく喋ってくれた」(向井氏)。
モデレーターの藤井は、沖縄での実証実験を現地で取材した。その際、画面内に3人のキャラクターが表示されていたことが印象的だったという。「3人のキャラクター同士が会話していて、沖縄に関する小ネタをラジオのように聞き流せるし、一方で『美味しいレストランはどこ?』といった質問にも答えてくれる。Google Homeのような(人間とAIの)1対1ではなく、1対多。3人の会話に混ぜてもらうような感覚が味わえた」(藤井)。

向井氏によれば、見た目上のキャラクターを3人用意することで「会話している感」が醸成されるのだという。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法
絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法 .jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話  「ストリートビュー」が捉えたクレイジーすぎる光景38連発
「ストリートビュー」が捉えたクレイジーすぎる光景38連発