AIが作ったコンテンツが世に広まっていくと、果たして社会にはどんな影響があるのか。まずは低コストでコンテンツを大量に産み出せるようになるため、知の豊富化が進むと考えられる。福井氏は例として、AP通信によるマイナー競技の試合結果記事自動化を挙げる。「米国野球のマイナーリーグはチーム数が100以上。その全試合の記事を自動配信している。従来なら到底できなかったが、記者を派遣することなく、今やスコアさえ送ってもらえば記事になる。それを低コストで配信できれば、ホームタウンを離れた人にも読んでもらえる。ビジネスの可能性としては計り知れない」(福井氏)

反面、コンテンツが増えれば価格破壊が進む。例えば、ある1人の小説家が産み出すコンテンツは、全部が全部、最高品質とは限らない。ルーチンワーク的に生活のために執筆があり、その日常の中から稀に超高次元の作品が生まれる。しかしAIがこうした日常的なレベルの執筆を代替できるようになると、小説家の収入が減り、高次元の作品が生まれる可能性を潰す恐れもある。
「パクリ」の増加も懸念材料である。AIは元々あるデータやコンテンツを元に、新たなコンテンツを作る。しかしその加工行程はブラックボックスになっていて、盗用などが疑われても、その実態を証明するのが難しい。
2016年末に大きな問題となったDeNAなどのまとめサイト問題では、記事の無断転用にあたって「リライトツール」の存在が取り沙汰された。元記事を単純にコピー&ペーストするのではなく、このツールで「てにをは」を自動で書き換え、検索エンジンでの低ランク評価を回避する目的で使われたとみられる。
福井氏が試した限り、このツールは性能面では決して優れたものではなかった。しかし今後は、AIの進化によって、変換品質は当然向上すると予想される。

加えて、日本の裁判の判例では、著作権侵害を証明するためのハードルは高いとされる。「(元の文章と)かなり似ていないと、著作権侵害の判決は出ていない。『明らかに元ネタにしているね』という程度ではダメ(編注:侵害を訴えた側が勝訴できない)。裁判になっても侵害判決が出ない程度のリライトツールは、それほど開発が難しいと思えない。もしそんなツールが出てきたら『適法パクリ』が誕生するかもしれない」(福井氏)
また、AIコンテンツは、悪く言えば「コピーの連鎖」に過ぎない。マーケティング主導でヒット作の後を追うばかりになれば、まったくの新しい表現が生まれる可能性は低く、これでは「知の縮小再生産」にとどまってしまうとの声もある。
AIコンテンツのリスクを抑え、いかにメリットを最大化するか──これが今後の著作権を考える上で最も重要な部分だ。「AIコンテンツの著作権は今まさに設計段階。政府でもまさに議論が進められていて、固定された1つの答えが出ているわけではない」と福井氏は述べ、講演中に紹介した事例などをもとに、今後の方向性について皆で考えてほしいと呼び掛けた。
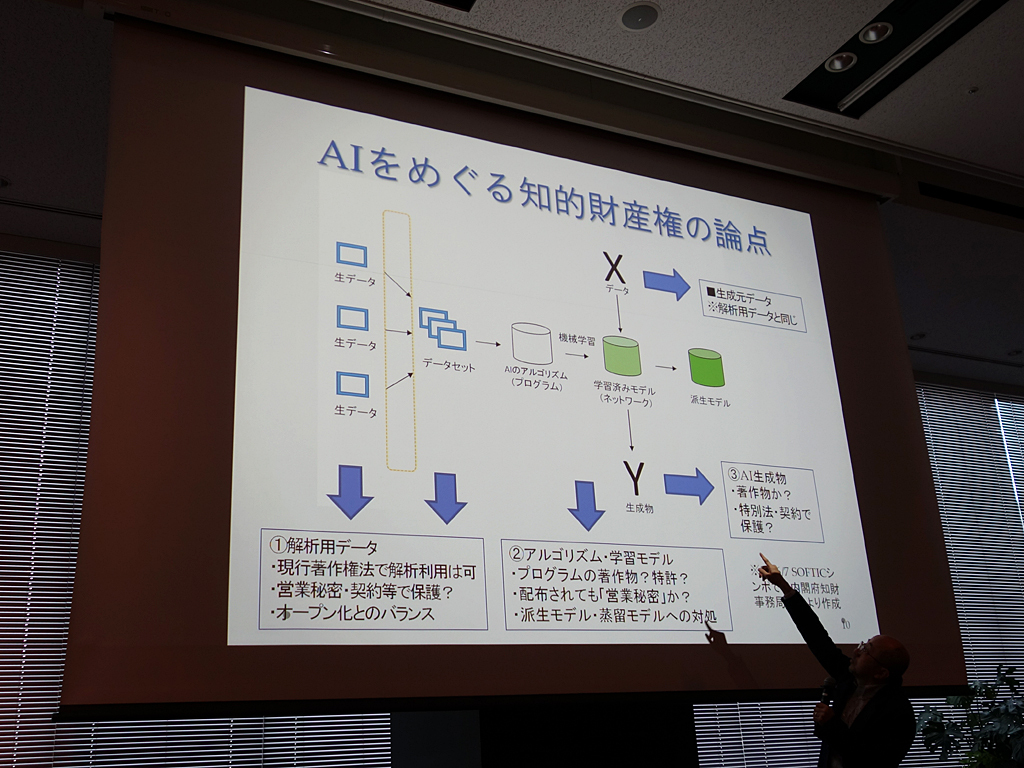
論点としてまず福井氏が挙げたのは「解析用データ」の扱いだ。AIの学習にあたって必要となるものだが、著作物は原則的に第三者利用に制限がある。では、著作権のないデータはどうだろうか。例として気象データ、医療データ、将棋の棋譜などが挙げられたが、これらも第三者利用から守ることはできる。一般的なウェブサイトと同様に、「利用規約」でAIを制限するのだ。
「(物理的にデータのダウンロードを制御する)アーキテクチャー面に加え、利用規約によって現在はデータが守られている。今後のAI・ビッグデータ時代は、利用規約の設計力が重要になってくるだろう。ここが知財戦略の第1歩」(福井氏)
とはいえ、技術や新サービスの発展には解析用データが欠かせない。利用規約による制限も過度な場合、独占禁止法に抵触する恐れが出てくる。国際的な潮流を考えれば、制限と利用促進のバランス取りが重要だと福井氏は指摘する。
なお、現行の著作権法47条の7では、電子計算機による情報解析目的のための著作物利用が認められている。これは諸外国と比べても踏み込んだ条文で、「日本は機械学習大国である」という指摘すらある。また、データ解析サービスなどを可能とするための著作権法改正案が2月に閣議決定されている。

CNET Japanの記事を毎朝メールでまとめ読み(無料)
 無限に広がる可能性
無限に広がる可能性
すべての業務を革新する
NPUを搭載したレノボAIパソコンの実力
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは  「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた  AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は