直接の(データベースへの)APIがあるわけではないにもかかわらず、多くの企業はdel.icio.usに蓄えられている情報を活用している。次のような例がある。
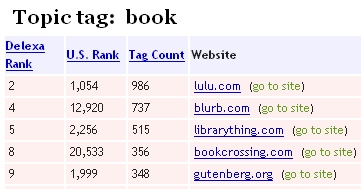
Delexaは、del.icio.usを使ってAlexaのサイトをカテゴリ分けする、面白くて便利なマッシュアップだ。例えば、「book」という単語でタグ付けされた有名なサイトを下にまとめてみた。
別の例はsimilicio.usと呼ばれるサイトで、del.icio.usを使って類似サイトを推薦する。例えば、同サイトによれば、Read/WriteWebに似ているのは次に示すようなサイトだ。
APIがないのにこれらのサービスはどうやってこういうことを実現しているのだろうか。答えは、標準化されたURLの活用と、ウェブスクレイピングと呼ばれる技術だ。これがどうやって動いているかを見てみよう。del.icio.usでは、例えば「book」というタグを持つすべてのURLは「http://del.icio.us/tag/book」というURLの下にある。また、「movie」というタグを持つものは「http://del.icio.us/tag/movie」の下、というふうになっている。このURLの構造は常に同じで、「http://del.icio.us/tag[タグ]」となっている。したがって、どんなタグが与えられても、コンピュータプログラムからそのタグを持つサイトのリストを含むページを取り出すことができる。ページが得られれば、プログラムからのスクレイピング、つまりそのページから必要な情報を抽出することが可能になるのだ。
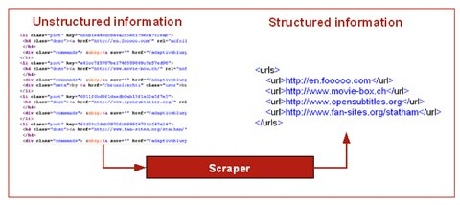
ウェブスクレイピングは、本質的にHTMLページのリバースエンジニアリングだ。ページから情報の断片を構文解析で取り出すことだと考えてもいい。ウェブページはHTMLでコーディングされており、情報を示すツリー状構造を持つ。実際のデータはレイアウト情報や補足情報と混ざり合っていて、コンピュータで扱いやすい形にはなっていない。与えられたHTMLのページから元のデータを取り出す方法を知っているプログラムがスクレイパーだ。それらのプログラムは、特定のマークアップの詳細を研究して、元のデータがどこにあるかを判断する。例えば、del.icio.usのページからURLを抽出するスクレイパーは以下の図のように機能する。このようなスクレイパーを適用すると、任意の与えられたタグに対して、そのタグを持つURLを調べることができる。

Read/WriteWebでは最近Yahoo! Pipesを取り上げた。これは、RSSフィードをリミックスすることに焦点を当てたYahoo!の新アプリケーションだ。最近始まったTeqloも類似の技術で、ユーザーがウェブサービスとRSSからマッシュアップやウィジェットを作れるようにすることに焦点を当てている。この2つのサイトよりも前に、Dapperがどんなウェブサイトにも使える一般的なスクレイピングサービスを開始している。Dapperはウェブページのスクレイピングを視覚的なインターフェースで手助けする興味深い技術だ。
Dapperは、開発者にいくつかのサンプルページを定義させ、次にマーカーを使って似たような情報を示させる。これは単純に見えるが、これを実現するのに、Dapperは背後で複雑なツリーマッチングアルゴリズムを使っている。ユーザーが一度ページ上の情報に似た情報の断片を定義するとそれをフィールドにできるようになる。ページ上の他の情報についても同じ処理を繰り返せば、開発者は構造化されていないページから一連の構造化された情報を取り出すクエリーを効率よく定義することができる。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ
 無限に広がる可能性
無限に広がる可能性
すべての業務を革新する
NPUを搭載したレノボAIパソコンの実力

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は  「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた .jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話