チェスではロボットに決して敵わないことを人間はほぼ受け入れたが、今度はそのロボットですら、他のロボットには決して敵わないことを受け入れざるを得なくなった。
新たな人工知能(AI)プラットフォーム「AlphaZero」は、人間による介入なしに、囲碁、チェス、将棋をゼロから学習できる。AlphaZeroはディープニューラルネットワーク(DNN:深層神経回路網)を利用して3種のボードゲームをすぐに習得し、「史上最強のプレイヤー」になった。

AlphaZeroは現地時間12月6日、「Science」に掲載されたDeepMind Technologiesの研究論文で発表された。DeepMindは、Googleの親会社であるAlphabet傘下の英AI企業で、何年も前から囲碁AIを手がけてきた。2017年、DeepMindは囲碁AIの世界チャンピオンだった「AlphaGo」を引退させたが、AIの開発は続けていた。DeepMindの研究はAlphaZeroで頂点に達した。
AlphaZeroは、3種のボードゲームで以下に挙げた世界最高のAIと対局した。
どのゲームでも、AlphaZeroはゲームの基本的ルールに関する知識を与えられただけだった。各AIマスターとの対局に先立ち、自分自身との対局を数百万局こなした。最初は勝つためにランダムな戦術を試みていたが、「強化学習」(Reinforcement Learning)と呼ばれるトライアル&エラーのプロセスを通じて、どの戦略が最もうまくいくかを徐々に学習した。
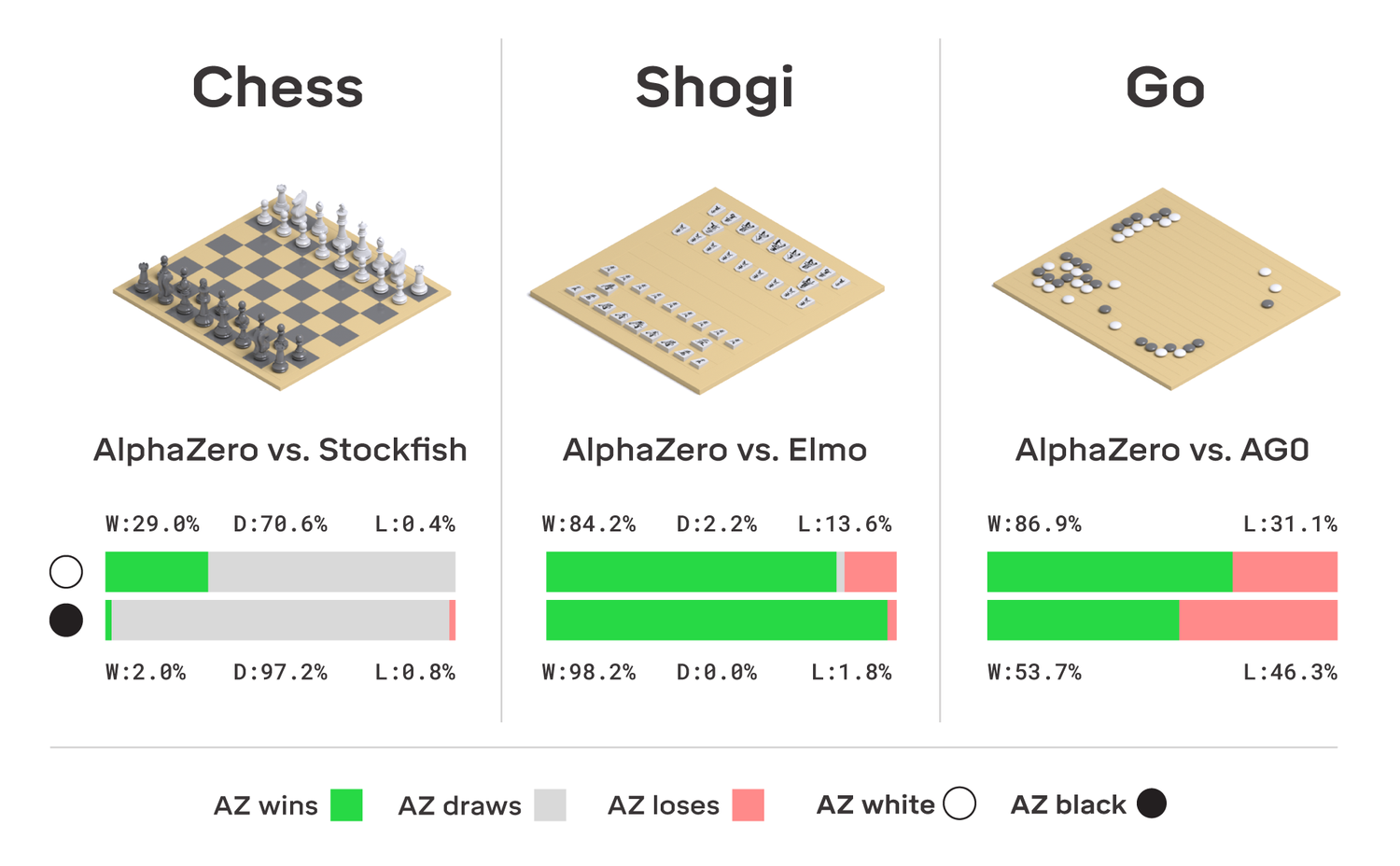
訓練と学習のプロセスは、グーグルの機械学習向けプロセッサ「Tensor Processing Unit」(TPU)5000基を使用し、チェスで9時間、将棋で12時間、囲碁で13日間かかった。参考までに、TPU 1基だけでも「Google Photos」で1日に1億枚以上の写真を処理できるため、AlphaZeroはかなり強大な処理ハードウェアと言える。学習完了後、AlphaZeroはAI同士の対局に臨んだ。
そして、相手をことごとく打ち破った。
この研究で独特なのは、学習アルゴリズムを「モンテカルロ木探索」(MCTS)と呼ばれる「検索手法」と組み合わせた点だ。MCTSは、囲碁AIプログラムが次に打つ手を識別する手法だ。DeepMindチームはこれと同じシステムをチェスと将棋にも使い、他の複雑な古典的ゲームにも応用できることを初めて示した。
おそらく人間のチェスプレイヤーにとって最も興味深いのは、AlphaZeroが、人間から知識を与えられることなく、これまでに見られなかった戦略や斬新な考え方を実践したことだろう。その攻撃的姿勢と極めてダイナミックな対局は、DeepMindのブログにコメントを寄せたチェスのグランドマスターMatthew Sadler氏を驚かせた。
こうした独自の戦略と能力を備えたAlphaZeroは、チェスプレイヤーにとって優れた教育ツールになる。これまでに見たことのない戦術的な戦い方を取り入れられるからだ。
AIが人間を打ち負かすという筋書きは、ゲームの世界ではかなりおなじみのもので、ボードゲームや、「Dota 2」などの複雑なマルチプレイヤー型ゲーム、そしてもちろん囲碁でも、ロボットは人間を打ち負かしている。
だからといって、AIが文字通り、これまでに発明されたあらゆる対戦型ゲームで人間を打ち負かしつつあると言えるだろうか?いや、そうとも言えない。今回、DeepMindが利用した3種のボードゲームは際立って複雑だが、いずれも2人で戦うゲームであり、次の手を打つのに必要なすべての情報が常に目に見えているという点で、AIにやや有利だ。
この記事は海外CBS Interactive発の記事を朝日インタラクティブが日本向けに編集したものです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ
 無限に広がる可能性
無限に広がる可能性
すべての業務を革新する
NPUを搭載したレノボAIパソコンの実力

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は  絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法
絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法  なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは