構造化されていない情報に関する基本的な論点を理解するために、次の例を考えて欲しい。HTMLで書かれた本とXMLで書かれた本の記述だ。ここに、ウェブページのソースでよく見られる典型的な表現を示す。

これを、XMLよく使われる典型的な表現と比較してみる。

HTMLは情報の構造を捉えておらず、情報と表現が混在している状態だ。一方XMLは、構造だけに焦点を当てており、その情報がどのように表現されるべきかについては何も示されていない。何十億という今日のウェブページが持っているのは、非構造化情報だ。人間にとっては、これは特に問題ではない。人間は意味を読み取るのに長けており、理解するのにXMLの原始的な注釈など必要ないからだ。しかしコンピュータにとっては、構造の欠如は根本的な問題だ。コンピュータは構造のない、標準化されていない情報を上手に解釈することができない。
人間がウェブを作るずっと以前に、リレーショナルデータベースが作られた。リレーショナルデータベースは、今日多くの企業やウェブサイトが基盤とするプラットフォームだ。リレーショナルデータベースが素晴らしいのは、情報を構造化された形で示してくれることだ。
Structured Query Language(SQL)として知られるクエリ言語が、単一のデータベーステーブルに収められた情報を取り出すのを支援する。より重要なのは、SQLが複数のデータベーステーブルの情報を関連づけたりそこから選択したりするクエリもサポートしていることだ。単純に言えば、SQLはデータのリミックスを可能にする。これに対する唯一の前提条件は、データが構造化されていることだ。
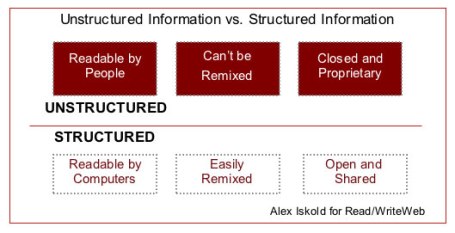
他方、情報が構造化されてない場合には、情報の格納は個別のサイロのなかで効率化される。サイロは外部に開かれておらず、また可搬性もない。こうした表現形式はクリエータ側には容易に理解されるが他のアプリケーションやWebサービスがデータを活用するのは容易ではない。ある意味では、ウェブ上の他のデータとリミックスすることができないのでかえって無駄が多いともいえる。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ
 プライバシーを守って空間を変える
プライバシーを守って空間を変える
ドコモビジネス×海外発スタートアップ
共創で生まれた“使える”人流解析とは

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法
絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法  「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた  「ストリートビュー」が捉えたクレイジーすぎる光景38連発
「ストリートビュー」が捉えたクレイジーすぎる光景38連発