rinnaは12月7日、大規模言語モデルGPTを活用した日本語音声認識モデル「Nue ASR」を開発したと発表した。同モデルは、商用利用可能なライセンスとして公開されている。

同社によると、AI技術の進歩により、従来では困難であった処理もAIで実現可能となりつつあるという。
こうした飛躍的な進展は、大量のデータから事前学習された基盤モデルを活用することで達成。特に、テキストを処理するための基盤モデルである大規模言語モデルGPTは、自然言語による人間とコンピュータのインターフェースを実現し多くのサービスで利用されるようになっている。
テキストだけでなく、画像や音声の処理においても、タスクに適した基盤モデルを活用することで、高い性能が達成できることが報告されているという。
同社は、日本語の処理に適したGPT・BERT・HuBERT・CLIP・Stable Diffusionなど、テキスト・音声・画像に関する事前学習済み基盤モデルの公開により、日本語のAI開発を支えている。
2021年4月から公開してきたrinnaモデルのダウンロード数は累計440万を超え、多くの研究・開発者が利用しているという。
最近では、事前学習された基盤モデルを組み合わせ、さまざまなタスクをこなすAIが開発されている。
そこで今回、これまでに開発・公開してきた日本語に特化したテキスト基盤モデルGPTと、音声基盤モデルHuBERTを統合した音声認識モデル「Nue ASR」を開発。Hugging Faceに、商用利用可能なApache-2.0 Licenseで公開した。
日本語音声認識モデル「Nue ASR」は、テキスト基盤モデルGPTと、事前学習済みの音声基盤モデルHuBERTの間に畳み込み層を挟んで統合したモデル。モデル名の由来は、妖怪の「鵺(ぬえ)」。
事前学習済みの基盤モデルを活用することで、音声認識モデルの学習コストを軽減できるという。また、音声認識モデルの学習データには、約19,000時間からなる日本語音声コーパスReazonSpeechコーパスを用いている。
なお、テキスト生成の分野でデファクトスタンダードとなっているGPT構造を用いており、活発に開発されている最先端の手法を容易に導入可能だという。
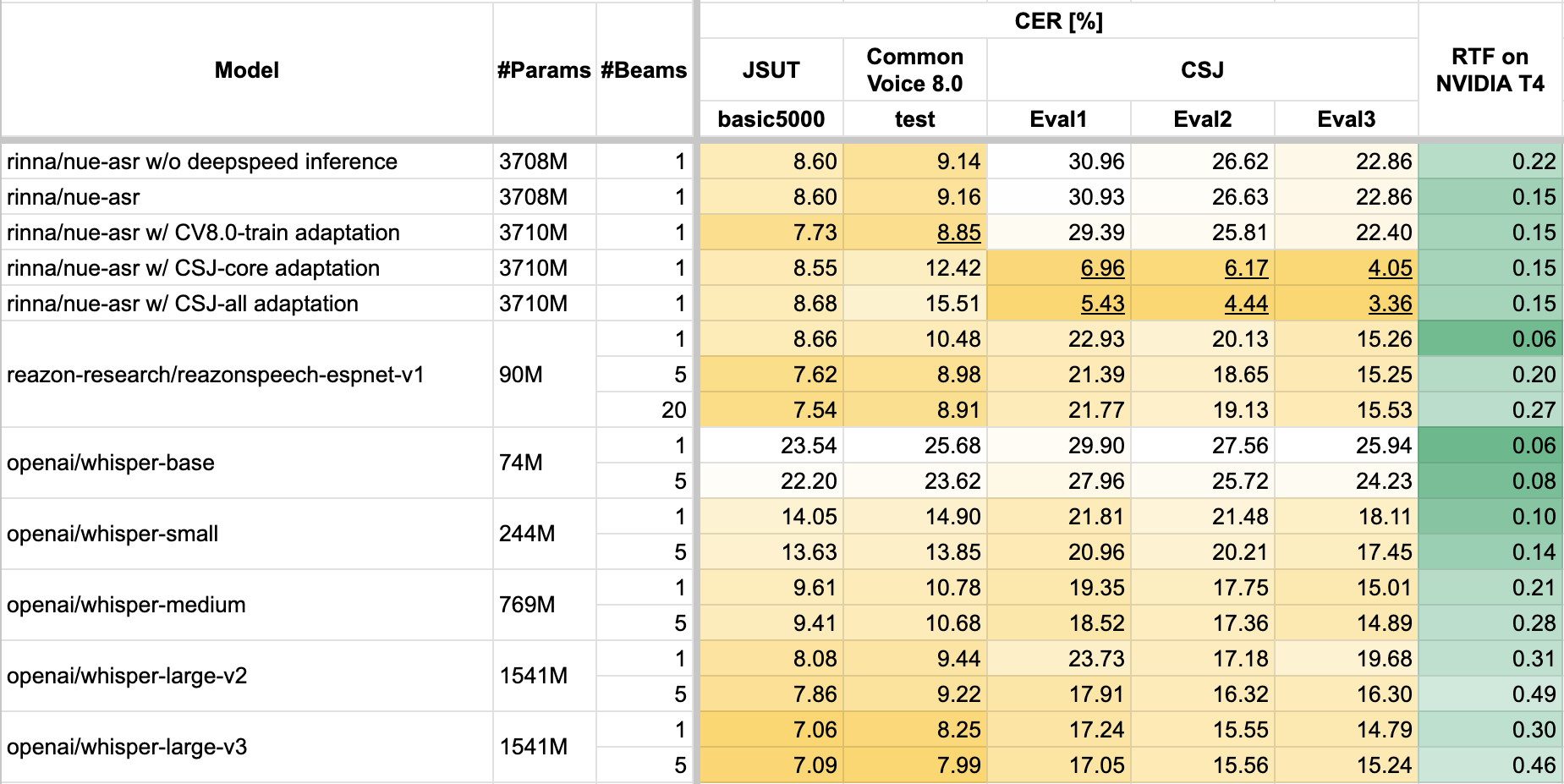
例えば、GPTの高速推論手法であるDeepSpeedを導入することで、リアルタイムファクタ(認識時間/音声の長さ)は、0.22から0.15に短縮した。CSJの学習セットを用いたドメイン適応のためのファインチューニングにより、CSJ Eval1テストセットの文字誤り率は30.93%から5.43%に改善している。
認識率や処理速度は、利用条件によってはOpenAI WhisperシリーズやReazonSpeechモデルに匹敵する性能を達成。デファクトスタンダードであるGPTを利用したNue ASRは、より高性能な事前学習済みGPTへの置き換えや、日々開発されるGPTのための手法を導入するなど、改良のための選択肢が多くあり、今後の性能改善も期待できるという。
同社は、人間とAIのコミュニケーションのために大規模言語モデルを用いたテキスト生成や音声合成の研究・開発・提供を実施。今回の音声認識モデルの開発により、音声対話に必要となる音声認識・テキスト生成・音声合成の実験を一通り遂行できたと考えているという。
これまでの実験で得られた多くの知見を生かし、大規模言語モデルの次の活用方法である音声対話の研究・開発・提供を進め、AIの社会実装を行っていくとしている。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 「ストリートビュー」が捉えたクレイジーすぎる光景38連発
「ストリートビュー」が捉えたクレイジーすぎる光景38連発 .jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話  なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは