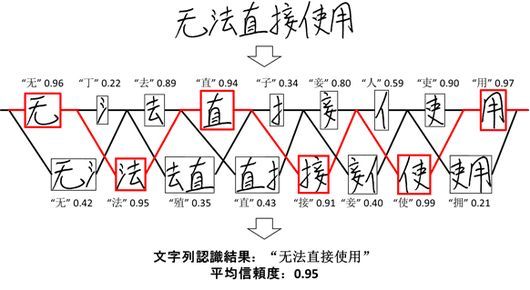
富士通研究開発中心有限公司(FRDC)と富士通研究所は11月8日、手書き文字列での画像認識において、信頼性の高い認識結果を出力できる人工知能モデルを開発したと発表した。中国語の手書き文字列の認識性能としては世界最高精度の認識率96.3%を達成した。
中国語での単一の手書き文字では、深層学習をベースとしたAIモデルが、すでに人間の認識能力を超えている。しかし、手書きの文字列に適用した場合、1つの文字の区切りを正しく判別できず、部首やつくりなど文字ではない画像も検出してしまい、文字の区切りを判別できない課題があった。
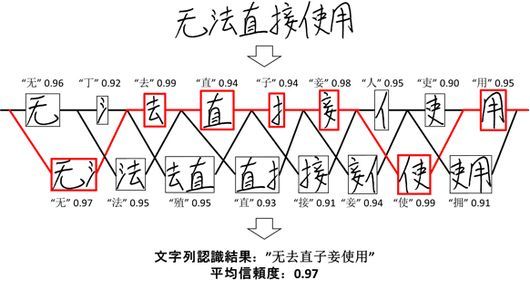
AIを活用した従来の手書き文字列の認識は、文字の教師サンプルを用いて、人間が認識するときに使う多数の文字パターンの特徴を学習する。次に文字列の空白部分から、部首とつくりのように複数領域に分割し、その領域が1つの文字を表す場合と、隣り合う領域を組み合わせて1つの文字になる場合に分けて、候補となる文字と信頼度を算出する。
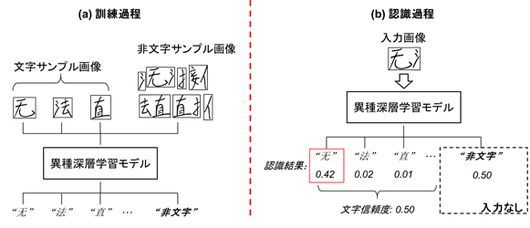
最終的に平均信頼度の最も高い組み合わせを選択することで文字列の認識結果として出力される。今回、部首やつくりなどのパーツや、文字にならないパーツの組み合わせからなる非文字の教師サンプルによる異種深層学習モデルにより、正しい文字のみに高い信頼度が出力される技術を開発した。
なお、異種深層学習モデルには、従来の文字の教師サンプルと、非文字の教師サンプルの2種類が含まれる。中国語文中で隣り合って現れやすいパーツの組み合わせを、非文字の特徴として記憶させて重みづけすることで、非対称な構造の深層学習モデルに対しても、効果的に学習できるようになった。
今回の認識技術により、中国科学院自動化研究所「Institute of Automation, Chinese Academy of Sciences」 が2010年に公開し、学会で標準として用いられている手書き中国語データベースのベンチマークにおいて、従来技術に比べて5%上回る96.3%の最高精度を達成している。
富士通では、スペースによる単語の区切りのない、中国語、日本語、韓国語などの言語に対して有効な技術だとしている。2017年には、富士通のAI技術「Human Centric AI Zinrai(ジンライ)」に実装し、日本向けソリューションに適用する予定だ。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす
 プライバシーを守って空間を変える
プライバシーを守って空間を変える
ドコモビジネス×海外発スタートアップ
共創で生まれた“使える”人流解析とは

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は  絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法
絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法 .jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話