Googleは米国時間12月16日、特定の単語や成句がどの程度頻繁に書籍に出現しているかを過去5世紀にわたって追跡し、表示できるツール「Google Books Ngram Viewer」を公開した。
Google Labsの研究者たちが発表した同ツールは、書籍のデジタル化という、時として論議を呼ぶプロジェクトをGoogleが2004年に開始して以来、1500万点以上という膨大な書籍をスキャンした結果を分析する。分析対象は、Googleが「コーパスのサブセット」と呼ぶ、これまでに出版された全書籍のおよそ4%にあたる500万点以上の書籍のデータだ。これら500万点以上の書籍に出現する約5000億もの語句を追跡することで、Ngram Viewerは過去に遡って言葉の歴史と使用頻度の推移を示してくれる。
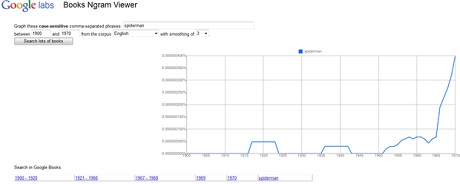
Ngram Viewerの使い方は簡単だ。単語や成句(5語まで)を入力すると、検索した語句が500年近くの間、どの程度頻繁に書籍に出現しているかを折れ線グラフで表示する。デフォルト設定では英語で書かれた書籍を検索するが、別の「コーパス」もしくは書籍のカテゴリ(アメリカ英語、イギリス英語、英語のフィクション、中国語、フランス語、ドイツ語、ロシア語、スペイン語など)にも検索対象を変更できる。
追跡する期間も、1500年から2008年までの全期間、または任意の期間を設定できる。
また複数の語句をコンマで区切って入力すれば、それぞれの語句の使用頻度を比較できる。
情報の生成に利用される実際のデータセットの基礎になっているのは、ハーバード大学の研究者たちの研究プロジェクトだ。「数百万冊規模のデジタル化された書籍を利用した文化の定量分析」という新しいツールに関する論文が、16日付けのScienceでオンライン公開されている。
 提供:Google
提供:Google
この記事は海外CBS Interactive発の記事を朝日インタラクティブが日本向けに編集したものです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する
