Googleは1月13日、オープンソース提供している機械学習システム用ツールキット「TensorFlow」について、都内でメディア向け説明会を開催した。TensorFlowの開発者が概要を解説したほか、オープンソース化の目的や今後の展望を述べ、さまざまな質問に直接答えた。

説明を担当したのは、Googleエンジニアリング部門リサーチサイエンティストのMike Schuster氏。同氏は、奈良先端科学技術大学で工学博士号を取得し、NTTでニューラルネットワークや音声認識システムの研究開発に携わるなど、日本と縁の深い人物である。
Googleでは音声認識システムの開発に取り組み、同社初の日本語および韓国語用の音声認識モデルを構築。その後、大規模ニューラルネットワークの実現を目指すプロジェクト「Google Brain」に参加し、現在はTensorFlowの開発を担当している。
同氏の開発するTensorFlowは、Googleとして第2世代に相当する機械学習(マシンラーニング)システム。ニューラルネットワークに膨大なデータを与えて“学習”させ、新たなデータを適切に解析させる、というシステムだ。このところ深層学習(ディープラーニング)という用語をよく耳にするが、ニューラルネットワークとディープラーニングは変わりないそうだ。
第2世代のシステムだけあり、TensorFlowは強力かつ高速になっている。複雑なモデルを構築でき、モデルの設定を動的に変えられる。しかも、モデルに設定可能なパラメータの数が、TensorFlowは数十億個レベルに増えた。学習用のデータは、数十億個も与えられる。機能がモジュール化されており、研究者が新たなアイデアを短時間でモデル化できるようになった。
そして、マルチスレッドやマルチプロセッサ、マルチマシンの分散処理により、処理が初代システムに比べ2倍以上速くなった。その結果、膨大なデータを与えても高速に学習され、モデルが機能するまでにかかる期間が短縮された。
TensorFlowで使うモデルは、大きく分けて「Dtataflow Graph(データフローグラフ)」と「Sequence Model(シーケンスモデル)」の2種類。
前者は、写真の被写体がどのようなものであるか推測したり、写真内の看板から数字や文字を読み取ったりすることに使える。例えば、花の写真を大量に“学習”させておくと、新たに“見せられた”写真に写っているものが花である確率を数値で示す。現在は、単に花と別のものを区別するだけでなく、ハイビスカスやダリアといった花の種類まで見分けられるレベルに達した。
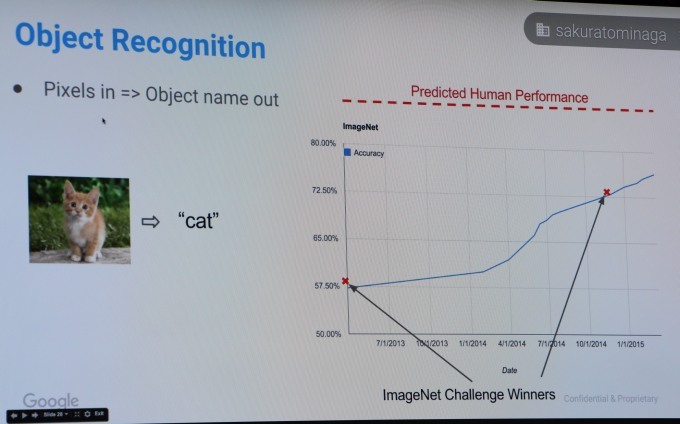
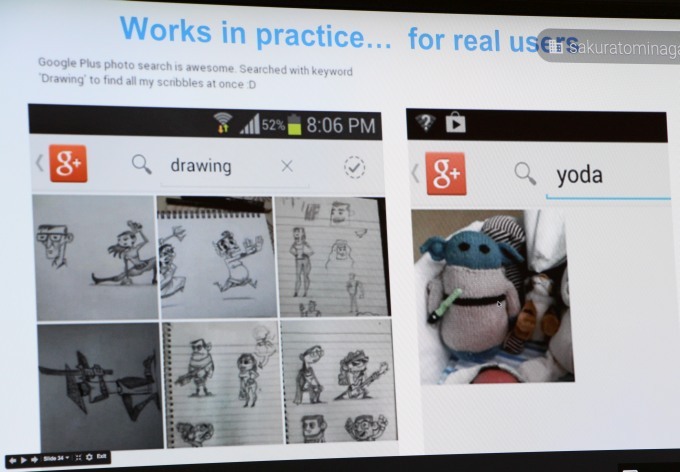
後者のSequence Modelは、時系列に音が並んだ音声、文字が一列に並んだテキストなどを扱うモデル。音声に適用して音声認識、テキストに適用して機械翻訳といったことに応用可能。実際にTensorFlowで翻訳を実行させたところ、現行の機械翻訳と同じレベルの結果が得られたという。
さらに、Dtataflow GraphとSequence Modelを組み合わせると、写真を画像認識し、その内容を文章で表現する、といった自動処理まで成功している。


そんな驚くレベルの処理を自動実行できるTensorFlowをオープンソース化した理由について、Schuster氏は、多くの研究者が多彩なアイデアを手軽に実現できるツールを広く公開することで機械学習の知見を深めたい、と説明した。機械学習に関する特許も申請はしているが、それを振りかざして他者を排除するつもりはないとした。
TensorFlowの技術はすでにGoogle内部で使われており、多くのユーザーが「Gmail」「Photos」「Maps」「YouTube」「Translation」といったサービスを介して恩恵を受けている。同様の応用がGoogle外部でも広まれば、TensorFlowの改善にもつながると期待する。

今後は、メモリ使用量の削減や処理速度の向上はもちろん、現在のLinuxおよびOS Xに加えWindowsでも使えるようにして、利用可能なOSやデバイスを増やす考え。
また、TensorFlowのマルチマシン処理はGoogleの社内システムでしか実行できず、現行オープンソース版は事実上マルチマシンに対応していない。この問題も、これから解決したいとした。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 「チャンスは蓄積できない」
「チャンスは蓄積できない」
先端分野に挑み続けるセックが語る
チャレンジする企業風土と人材のつくり方
 進化し続ける挑戦
進化し続ける挑戦
NTT Comのオープンイノベーション
「ExTorch」5年間の軌跡
 無限に広がる可能性
無限に広がる可能性
すべての業務を革新する
NPUを搭載したレノボAIパソコンの実力
 日本版『スターリンク』の夢は実現するか
日本版『スターリンク』の夢は実現するか
日本のインターステラテクノロジズが挑む
「世界初」の衛星通信ビジネス
 議事録作成もデジタル変革!
議事録作成もデジタル変革!
地味ながら負荷の高い議事録作成作業に衝撃
使って納得「自動議事録作成マシン」の実力

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは  AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は  「ストリートビュー」が捉えたクレイジーすぎる光景38連発
「ストリートビュー」が捉えたクレイジーすぎる光景38連発