Googleは米国時間7月16日、Metawebを買収したことを発表した。Metawebは2005年に設立され、世界中のあらゆる物事やその特性、その結びつきに関するデータベースを構築してきた。
Metawebには、Googleとの共通点がある。例えば、ユーザーは同じ存在を表現するのにさまざまな異なる用語を使用する可能性があり、また、同じ名前が異なる存在を表す可能性もあるという課題を両社ともに抱えている。「Freebase」と呼ばれるメカニズムによって他人が自由に貢献寄与することのできるMetawebのデータベースは、1200万に及ぶそうした存在のさまざまな属性を管理している。
Googleは、数多くの検索クエリを処理できるが、Metawebの情報があればさらに多くのクエリを扱うことができるようになると、Googleの製品管理担当ディレクターを務めるJack Menzel氏はブログ投稿で述べた。
同氏は、「われわれは、リッチスニペットや検索結果に回答を提示する機能のような取り組みによって、われわれのウェブに対する知識を、検索をよりよくするために応用し始めている」と述べたが」と述べたが、それでもまだGoogleの範囲を超えた検索が一部存在する。「『授業料が3万ドル未満の西海岸にある大学』や『40歳以上の俳優で少なくとも1度アカデミー賞を受賞している人』といった検索はどうだろうか?これらは難しい質問だが、Metawebとともに取り組めば、よりよい回答を提供できるようになると思う。そのためにMetawebを買収した」(Menzel氏)
今回の動きは注目に値する。なぜなら、Googleは世界の情報を整理し、それを世界中からアクセス可能にするという同社のミッションにおいて通常、他のデータの整理に同社独自のアルゴリズムを適用するからだ。この方法の利点は、Googleは情報を作成する必要はなく、ただ情報を処理すればよいという点にある。
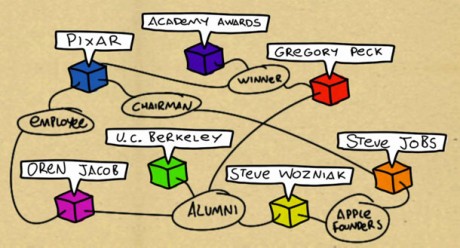 提供:Screenshot by Stephen Shankland/CNET
提供:Screenshot by Stephen Shankland/CNET
この記事は海外CBS Interactive発の記事を朝日インタラクティブが日本向けに編集したものです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 ビジネスの推進には必須!
ビジネスの推進には必須!
ZDNET×マイクロソフトが贈る特別企画
今、必要な戦略的セキュリティとガバナンス
 議事録作成もデジタル変革!
議事録作成もデジタル変革!
地味ながら負荷の高い議事録作成作業に衝撃
使って納得「自動議事録作成マシン」の実力
 CES2024で示した未来
CES2024で示した未来
ものづくりの革新と社会課題の解決
ニコンが描く「人と機械が共創する社会」

 近い将来「キャッシュレスがベース」に--インフキュリオン社長らが語る「現金大国」に押し寄せる変化
近い将来「キャッシュレスがベース」に--インフキュリオン社長らが語る「現金大国」に押し寄せる変化
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する
 「当たり前の作業を見直す」ことでパレット管理を効率化--TOTOとユーピーアールが物流2024年問題に挑む
「当たり前の作業を見直す」ことでパレット管理を効率化--TOTOとユーピーアールが物流2024年問題に挑む
 ハウスコム田村社長に聞く--「ひと昔前よりはいい」ではだめ、風通しの良い職場が顧客満足度を高める
ハウスコム田村社長に聞く--「ひと昔前よりはいい」ではだめ、風通しの良い職場が顧客満足度を高める
 「Twitch」ダン・クランシーCEOに聞く--演劇専攻やGoogle在籍で得たもの、VTuberの存在感や日本市場の展望
「Twitch」ダン・クランシーCEOに聞く--演劇専攻やGoogle在籍で得たもの、VTuberの存在感や日本市場の展望
