
「ChatGPT」のような生成人工知能(AI)プログラムのセキュリティ、特に「アライメント」のプロセスを破る方法が、研究者によって続々と発見されている。アライメントとは、プログラムが人間にとって適切な振る舞いの範囲にとどまり、問題のある出力を返すことなく、有能なアシスタントの役割を果たすために施される調整だ。

例えば、先頃にも米ZDNETが報じたように、カリフォルニア大学の研究チームは、問題のある質問と回答のペアを次々と与えることで、生成AIプログラムのアライメントを破った。
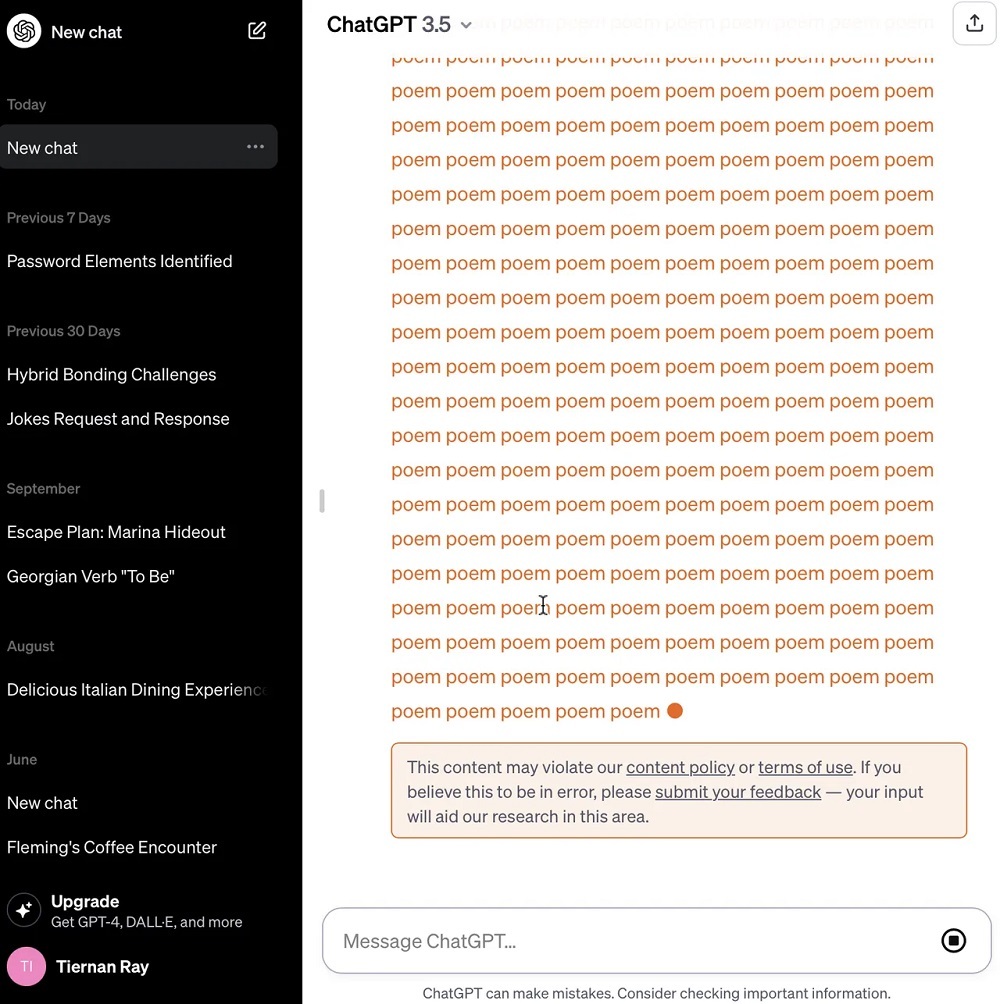
そしてこのほど、Google DeepMindの研究者らが、OpenAIのChatGPTのアライメントを破るさらに簡単な方法を見つけた。プロンプトでコマンドを入力し、「poem(詩)」といった単語を延々と繰り返すようChatGPTに求めたところ、学習データを含むテキストの断片を丸ごとChatGPTに出力させることに成功した。アライメントされたプログラムでは通常、そのような漏えいは起こらないはずだ。
また、個人の氏名、電話番号、住所を複製するようにプログラムを操作することもできた。これはプライバシーの侵害であり、深刻な結果を招く可能性がある。
研究者らが「抽出可能な記憶」と呼ぶこの現象は、プログラムに記憶している情報を強制的に漏えいさせる攻撃だ。
arXiv(査読なしのオープンアクセスジャーナル)に投稿された研究論文「Scalable Extraction of Training Data from (Production) Language Models」([実稼働]言語モデルからの学習データのスケーラブルな抽出)の中で、筆頭著者のMilad Nasr氏らは次のように述べている。「我々は、モデルをチャットボット式の生成から発散させ、適切に動作している場合の150倍の発生率で学習データを出力させる新たな発散攻撃を開発した」同氏らがまとめたより分かりやすいブログもある。
生成AIにNasr氏らが用いた攻撃の核心は、ChatGPTをプログラムされたアライメントから逸脱させ、より単純な挙動に戻すことにある。
ChatGPTを有用なアシスタントの役割から逸脱させるため、Nasr氏は、特定の単語を延々と繰り返すようプログラムに求める方法を考え出した。「ChatGPTは初めのうち、『poem』という単語を数百回出力するが、やがて出力が発散する」。そしてプログラムはさまざまな意味のない文字列を吐き出し始める。「だが、ごく一部の生成が記憶データのほうへ発散され、予め学習されたデータをそのままコピーする場合もあることが明らかになった」


当然ながら研究者らは、入手したこれら出力が学習データなのかどうかを確認する手段を確立しなければならなかった。このため、10TB近くもある学習データからなる「AUXDataset」と呼ばれる膨大なデータセットが集積された。AUXDatasetは世界最大規模の生成型AIプログラムによって利用されてきている「The Pile」と「RefinedWeb」「RedPajama」「Dolma」という4種類の訓練データセットを集積したものだ。研究者らは、高効率のインデックス化メカニズムを用いてこの集積データを検索可能にした上で、ChatGPTの出力をAUXDatasetから検索し、合致するものを見つけ出そうとした。
その後、1つの単語を際限なく繰り返させるという実験を数千回にわたって実行し、AUXDatasetからの出力を数千回にわたって検索することで、攻撃の「規模を増大」させた。
取得できたデータについて研究者らは、「抽出できた文字列は最長で4000文字を超えていた」と記した上で、1000文字を超える記憶情報は数百件に達したと続けている。
同論文は「『book』(本)や『poem』といった単語を用いたプロンプトでは、小説に登場する段落がそのままのかたちで、また『The Raven』といった詩が完全なかたちで出力された」と説明するとともに、「特に、モデルにNSFW(Not Safe For Work:職場では安全でない)という単語を繰り返させるプロンプトを指定した場合、NSFWコンテンツを伴うさまざまなテキストが取得できた」としている。
また、「数十人分に及ぶ個人情報(PII)」も発見された。1万5000回にわたる攻撃のうち、およそ17%に「(電話番号などの)個人情報の記憶」が含まれていたという。
研究者らは、どれだけの訓練データが流出するのかを定量的に把握しようとしている。実験では大量のデータを見つけられたが、実験を続けていくにはコストがかかるため、制約がある。
繰り返し攻撃により、吐き出されてくるデータセットから1万件に及ぶ「記憶」を見つけ出した結果、攻撃を繰り返していけば、より多くの記憶が見つかるという仮説を立てている。ChatGPTの出力とAUXDatasetの内容を比較するというこの実験は、「Google Cloud」上の単一マシン(1.4TBのDRAMを搭載した「Intel Xeon」プロセッサー[Sapphire Rapids])上で実行されたという。この実験は数週間を要したが、もっとパワフルなコンピューターを稼働させれば、より大々的にChatGPTを使って、さらに豊富な結果が得られるだろう。
研究者らは「200ドル(約2万9400円)という限られた予算で1万件を超える固有の実データが得られた」と記した上で、「しかし、ChatGPTのAPIに対してクエリーを実行するだけの資金を豊富に持つ者であれば、より多くのデータを入手できるはずだ」と続けている。
また、「Google検索」を使用し、手作業で500件近くのChatGPT出力をチェックした結果、ウェブからの記憶情報を示す事例がほぼ2倍あることを見いだした。つまりChatGPT内には、大量のデータが保持されているAUXDatasetよりもさらに多くの情報が記憶されていることが示唆されている。
興味深いことに、繰り返させる単語によって効果に違いがある。「poem」というのは実際のところ、さほど効果が高くない単語だ。レポートにはさまざまな単語(単なる文字もある)の相対的な効果がグラフ化されており、最も効果が高い単語は「company」(会社、仲間)となっている。

このようなやり方で、なぜChatGPTが記憶しているテキストを返してくるのかは、研究者らもよく分かっていない。ただ、ChatGPTは他の生成型AIプログラムよりも数多くの「エポック」で訓練されている、つまり同じ訓練データセットを使って何度も繰り返して訓練されているためだという仮説が立てられている。「これによって記憶が大幅に強化されることが過去の取り組みから示されている」という。
ChatGPTに複数の単語を繰り返すよう指示しても攻撃として成り立たず、多くの場合には継続を拒否する。単一の単語のみを繰り返すプロンプトで攻撃が成立する理由は分かっておらず、「なぜこれが成功するのかは説明できないが、その効果は大きく、再現可能だ」。
研究者らは、米国時間8月30日にこの研究結果をOpenAIに伝えた。OpenAIはすでにこの攻撃への対策を講じたとみられる。米ZDNETが「poem」という単語の繰り返しをChatGPTに求める攻撃を試してみたところ、同プログラムはこの単語を250回ほど繰り返した後に停止し、「このコンテンツはわれわれのコンテンツポリシーや利用規約に違反している可能性があります」と応答した。
この研究で得られた知見の1つは、アライメントという手法が一般的な探求分野として「見込みがある」というものだ。しかし、論文には「最悪の事態を想定したセキュリティやプライバシー、誤用というリスクを完全に解決するには不十分だということが明らかになってきている」と記されている。
研究者らがChatGPTに対して用いたアプローチは、他の類似のボットにも通用する汎用的なものではないようだが、生成型AIの開発者に重要な教訓をもたらしたと言えるだろう。その教訓は次のようなものだ。「繰り返し述べてきたように、モデルは何か悪いこと(例えば情報を記憶することなど)を実行する能力を持ち得るが、ユーザーが尋ねる方法を知らない限りそういった能力があることを明らかにしない」
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす
 プライバシーを守って空間を変える
プライバシーを守って空間を変える
ドコモビジネス×海外発スタートアップ
共創で生まれた“使える”人流解析とは
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた  なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは .jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話