
人工知能(AI)分野における2023年の出来事のうち、将来重大な影響を及ぼす可能性のあるものの1つは、「ChatGPT」を開発したOpenAIが3月に最新の大規模言語モデル(LLM)「GPT-4」を発表した際、このプログラムに関する詳細な技術情報を非公開にするという決定を下したことだ。

同社が突如として秘密主義に転換したことが、テクノロジー業界にとって大きな倫理的問題になりつつある。というのも、OpenAIとそのパートナーであるMicrosoft以外の誰も、両社のコンピューティングクラウド内のブラックボックスで何が起こっているのかを知り得ないからだ。
オックスフォード大学のEmanuele La Malfa氏とアラン・チューリング研究所およびリーズ大学の共同研究者らは9月、こうした問題をテーマとした論文をarXiv.org(査読なしのオープンアクセスジャーナル)に発表した。
この論文で、La Malfa氏らは「サービスとしての言語モデル」(Language-Models-as-a-Service:LMaaS)という現象を考察し、ユーザーインターフェースやAPIを介してオンラインでホストされているLLMについて言及した。このアプローチの主要な例が、OpenAIのChatGPTとGPT-4だ。
「商業的な圧力によって大規模かつ高性能なLM(言語モデル)が開発され、顧客向けサービスとして独占的にアクセスされる状態になった。これらのLMはユーザーのテキスト入力に対して文字列やトークンを返す。しかし、そのアーキテクチャー、実装、学習手順、学習データに関する情報は公開されておらず、内部状態を検査または変更することもできない」(論文)
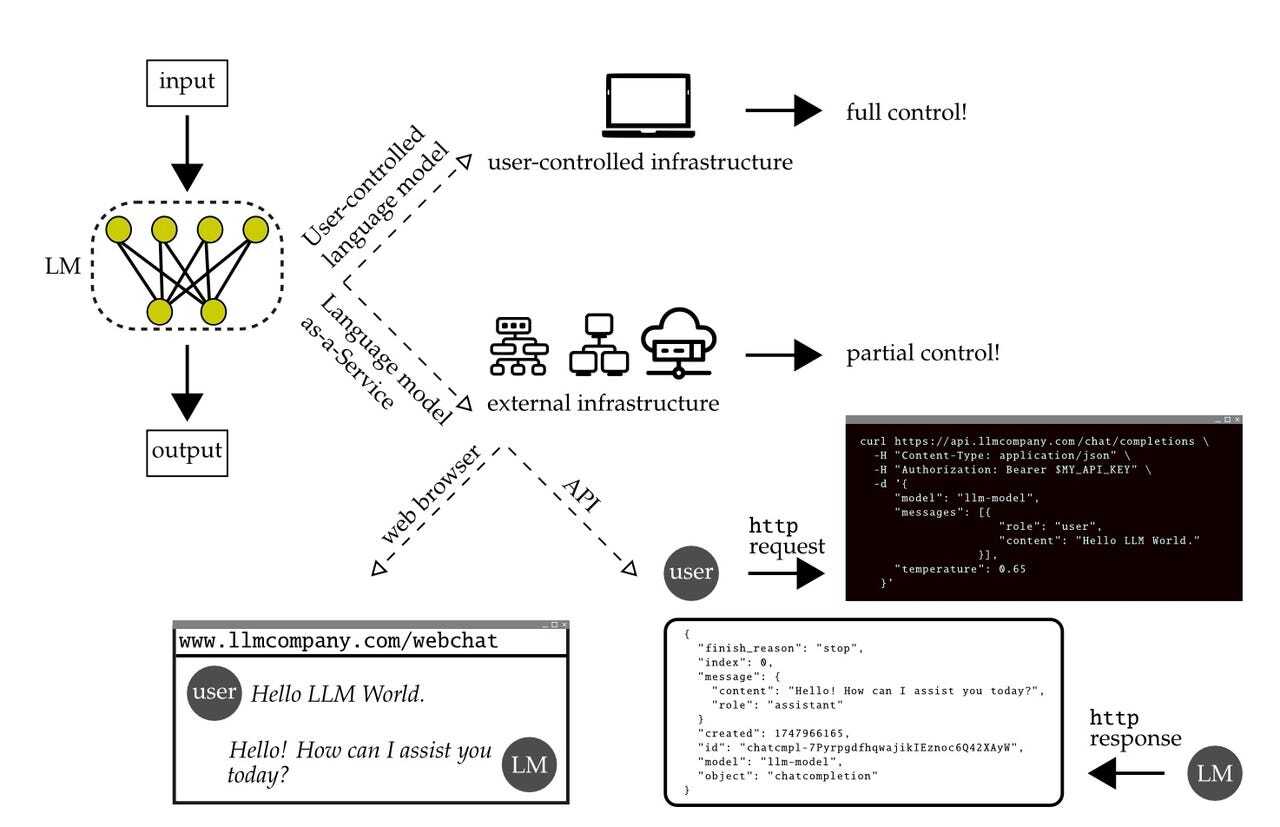
「アクセス制限はLMaaSに固有のもので、そのブラックボックス的な性質と相まって、一般の人々や研究コミュニティーがLMaaSをより良く理解し、信頼し、コントロールする必要性と相容れない」「このことは、この分野の核心部分において重大な問題を引き起こす。つまり、最も強力でリスクの高いモデルは、最も分析が難しいモデルでもあるということだ」
この問題は、OpenAIの競合他社、特にクローズドソースのコードに対抗してオープンソースのコードを利用している企業を含め、業界内で広く指摘されてきたものだ。例えば、画像生成AI「Stable Diffusion」などのツールを開発している生成AIの新興企業、Stability AIの最高経営責任者(CEO)Emad Mostaque氏は、どの企業もGPT-4のようなクローズドソースのプログラムを信頼できないと述べている。
同氏は4月に開催された報道陣と経営幹部らによる小規模な会合で、次のように述べた。「非公開データにはオープンモデルが不可欠になるだろう」「その中身をすべて把握しておく必要がある。これらのモデルは非常に強力だ」
La Malfa氏と同氏が率いるチームは、さまざまな言語モデルの資料を調査し、密室での開発によって、プログラムのアクセシビリティーと反復可能性、比較可能性、信頼性という4つの重要な観点に立った監査がいかに妨げられるのかを明確にした。
著者らは、これらはAI倫理において新たに出てきた懸念だとし、「これらの問題はLMaaSというパラダイムに特有のものであり、言語モデルにかかわる既存の懸念とは異なっている」と記している。
アクセシビリティーはコードを非公開にするという話と関係があり、著者らによるとこれは大規模な研究開発(R&D)予算を有する大企業に偏重したかたちで利益をもたらすという。
著者らは「計算処理に使えるリソースが企業間で大きく異なり、ごく一部の企業に集中している状況において、技術に優れているが計算処理についてはそうではない企業はジレンマに直面する。自社のLMaaSをオープンソースにすれば、市場でのプレゼンスや、コミュニティーによるコードベースへの貢献というメリットがある一方、モデルを支えるコードを公開することで競争上の優位性は、より豊富なリソースを有する企業によってあっという間に相殺されるおそれがある」と記している。
これに加えて、LMaaSプログラムの均一化された価格は、ツールへのアクセス機会という点で、経済発展が遅れている地域の人々にとって不利に働く。研究者らは「こういった問題を低減するための手始めは、LMaaS、より一般的に言えばスタンドアローンで広く普及するディスラプティブ技術としての従量課金型AIサービスについて、その影響を分析することだ」と示唆している。
もう1つの問題は、LLMの訓練方法における格差の増大だ。著者らによると、商業LLMは顧客のプロンプトを再利用できるため、公開されているデータのみを用いるプログラムに大きく差をつけられるという。
著者らは、LMaaSの商用ライセンスによって、「企業がサービスを提供/維持/改善できるよう、その企業にプロンプトの使用権が与えられる」ため、訓練データについて万人が想定できる共通の基準が存在していないと記している。
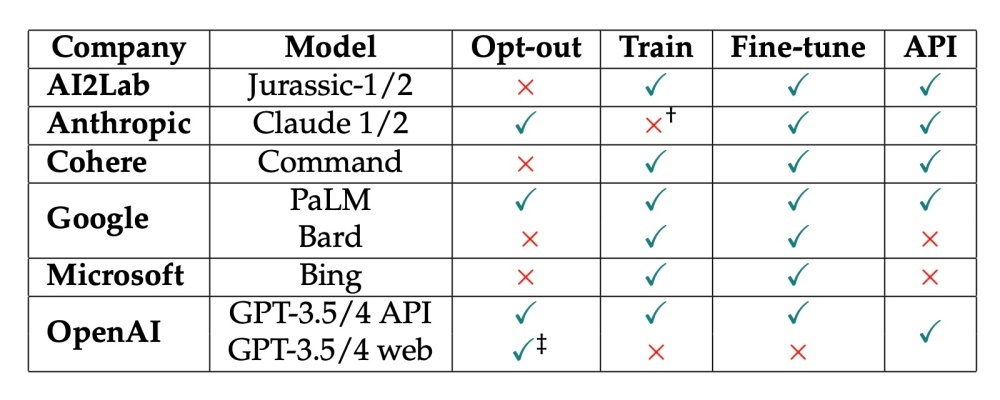
著者らは言語モデル別に、ユーザーのオプトアウトが可能なのか、訓練目的で顧客プロンプトを収集しているか、言語モデルの能力向上に向けた「微調整」を加えているのかを一覧できる表も掲載している。
La Malfa氏と同氏のチームは、さまざまなリスクを詳細に説明した後、4つの分野に取り組むための「仮の議題」を提唱し、「研究者や政策立案者、一般大衆がLMaaSを信頼できるようにするためのソリューションを見いだすために、コミュニティーとして活動する必要がある」と促している。
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ
 プライバシーを守って空間を変える
プライバシーを守って空間を変える
ドコモビジネス×海外発スタートアップ
共創で生まれた“使える”人流解析とは
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた  絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法
絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法 .jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話