
「コンピューターの父」呼ばれているAlan Turing氏にちなんで名付けられた「チューリングテスト」は、人工知能(AI)が本物の人間のように振る舞い、人を欺くことができるかを判定するためのテストだ。AIシステムが注目を集める昨今、AI開発企業のAI21 Labsは、このテストをオンラインで試せるゲームアプリ「Human or Not」(人かそうでないか)を開発した。
同社が4月半ばに公開したこのゲームアプリは、誰か(または何か)と2分間チャットし、その相手が人間かAIかを判断するというもの。自由に質問したり、回答したりできるが、2分経過したら、対話相手が人間または機械のどちらだったのか、答えを出さなければならない。
このアプリはチューリングテストとして過去最大規模となり、世界中から150万人超が参加し、1000万以上もの会話が行われた。AI21 Labsによると、人間とボットを正確に区別できたのは68%で、32%が判別できなかったという。
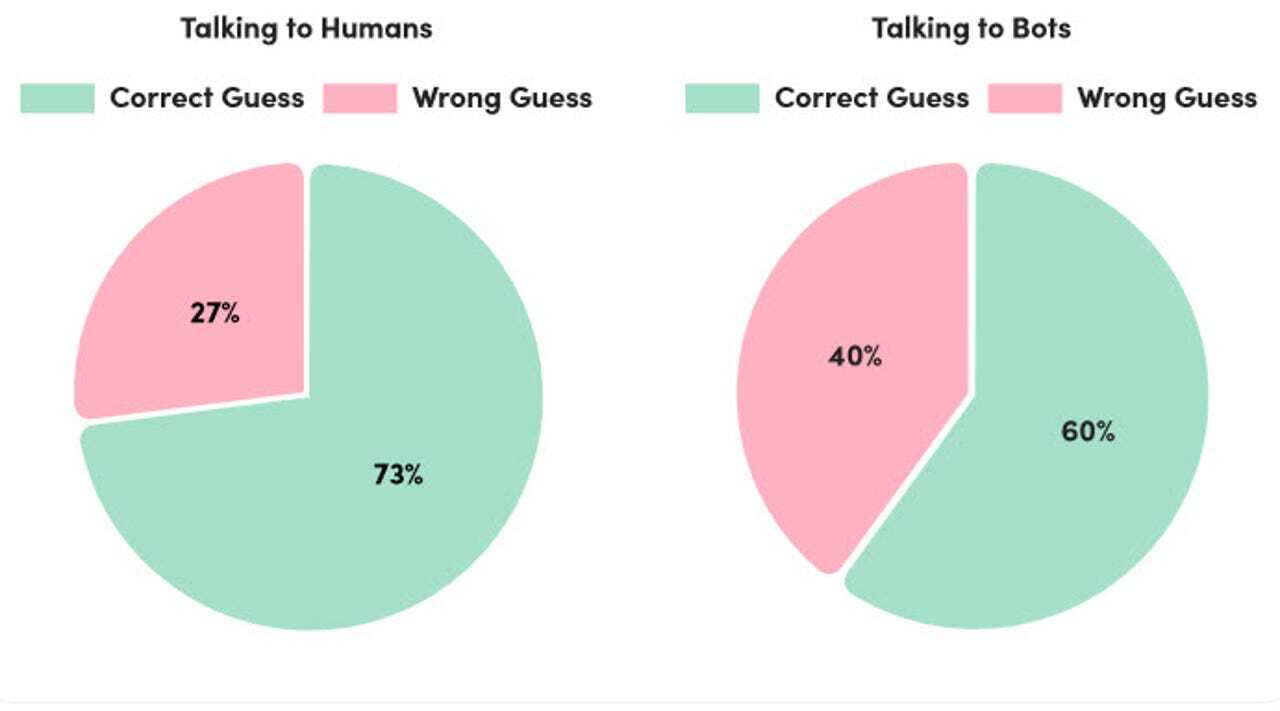
全体的に、相手が人間であることを識別する方が簡単だったようだ。人間とチャットしている時は、参加者の73%が正しく判断できた。一方、ボットが相手の場合、正しく推測できたのはわずか60%だった。
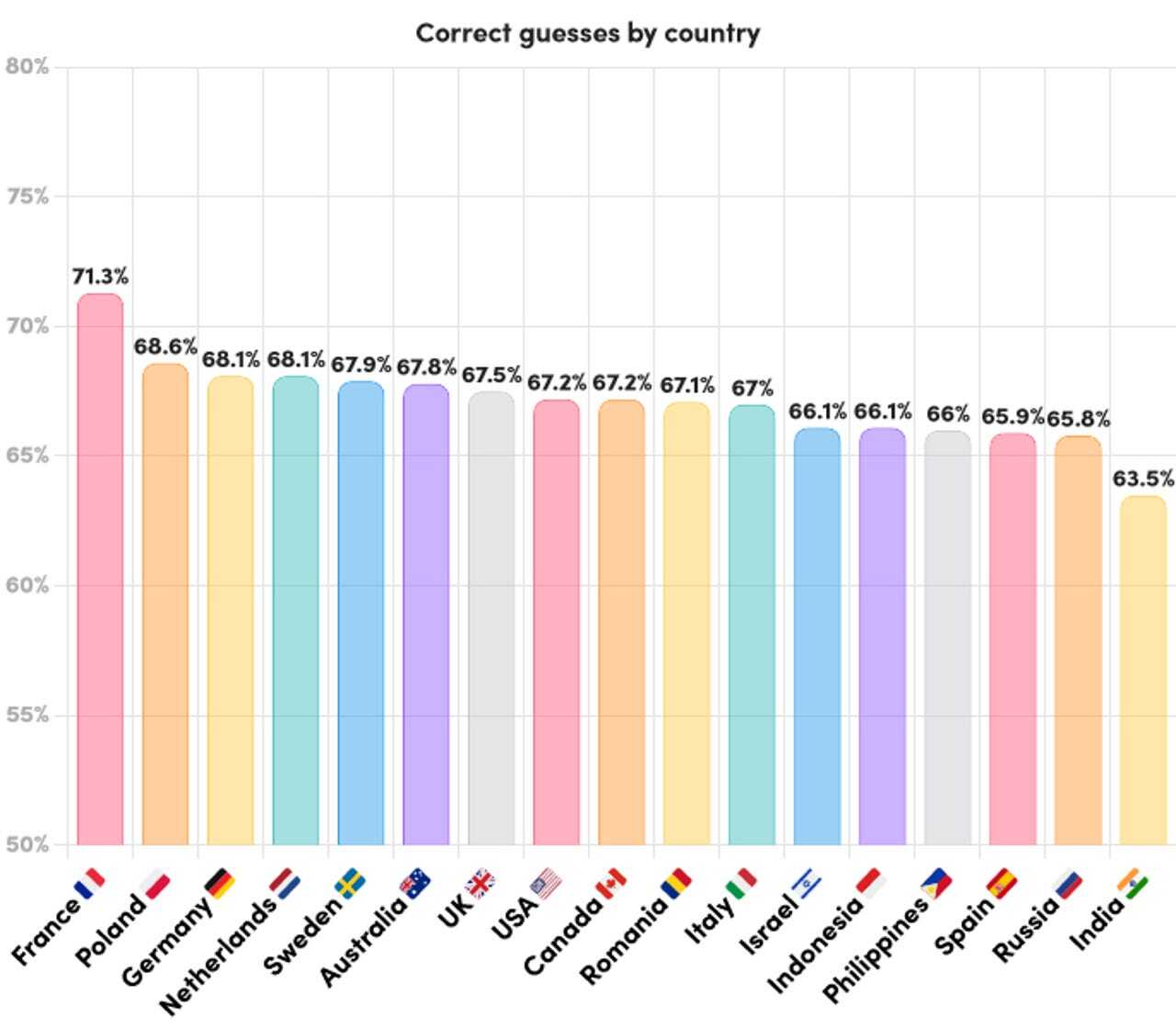
17カ国のうち、正解率が最も高かったのはフランスで71.3%、最も低かったのはインドで63.5%だった。米国は中間あたりの67.2%で、その他は、英国が67.5%、イタリアが67.0%、ロシアが65.8%などとなっている。
Human or Notが使用したAIボットは、「GPT-4」やAI21 Labsの「Jurassic-2」といった最上位クラスの大規模言語モデル(LLM)をベースにしている。これらのLLMは、チャットボットやAIツールがより人間に近いテキストを生成できるように、深層学習を利用する。AI21は独自のフレームワークも開発し、ゲームごとに異なるキャラクターを持つボットを作成したという。
参加者はさまざまな工夫をこらして、相手が人間なのかボットなのかを見極めようとした。しかし、AIは十分に訓練され、多くの情報を持っていたため、必ずしもうまくいかなかった。
例えば、チャット相手が綴りや文法でミスをしたり、スラングを使ったりすると、多くの人は相手が人間である可能性が高いと考えるが、言語モデルは特定の間違いやスラングを使うように訓練されていた。
また中には、AIの学習データには最近の出来事は含まれていないはずだと考えて、会話を最近の時事ネタに誘導しようとする者もいた。しかし、ゲームで使用された言語モデルの多くは、インターネットに接続されていたため、最新ニュースを把握していた。
ボットには私生活がないという前提で、名前や出身地などの個人的な内容を尋ね、その反応をうかがう者もいた。しかし、ボットはデータベースにある個人的なエピソードをもとに架空の人格を作り上げ、うまく回答することができた。
一方、違法行為に関するアドバイスを求めたり、不快な言葉を引き出そうしたりする試みは、ほかのトリックよりも、ややうまくいった可能性がある。これは、AIが「倫理的サブルーチン」に基づき、そうした要求には応じないはずだという考えに基づいている。
AI21 Labsは、この結果を詳細に調査し、ほかの主要なAI研究者や研究機関と共に、プロジェクトに取り組むと述べている。一般市民、研究者、政策立案者が、単なる生産性向上ツールとしてではなく、未来のオンライン世界を構成する一員としてのAIに対する理解を深めることができるよう支援したい考えだ。
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ
 プライバシーを守って空間を変える
プライバシーを守って空間を変える
ドコモビジネス×海外発スタートアップ
共創で生まれた“使える”人流解析とは
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは  AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は  「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた