アドビシステムズは11月6日、同社が開催する年次の大規模クリエイティブカンファレンス「Adobe MAX 2019」において、同社のプロダクトに搭載されそうな新技術を披露する「Adobe Sneaks」セッションを公開。11の未来の技術が初めて公開された。

Sneaksは、2日間のAdobe MAXのトリを飾るセッションということもあって毎年人気が高い。参加者はお酒を片手に披露される新技術の数々を楽しみ、興奮した様子だった。参加者はその後、打ち上げパーティー「Bear Bash」に流れ込む。
ここ最近のSneaksは、「作ってみました」から脱却し、いつプロダクトに実装されてもおかしくないクオリティの物が多い。実際、2018年のSneaksで発表された、被写体を検知して横動画を縦動画にスムーズにトリミングする技術は、「オートリフレーム」機能として2019年のPremiere Proに導入されている。今回の発表はどれも、アドビのAIプラットフォーム「Adobe Sensei」を活用しており、Senseiの成熟に合わせてこうした研究開発のスピードが上がっていることを示していると言える。
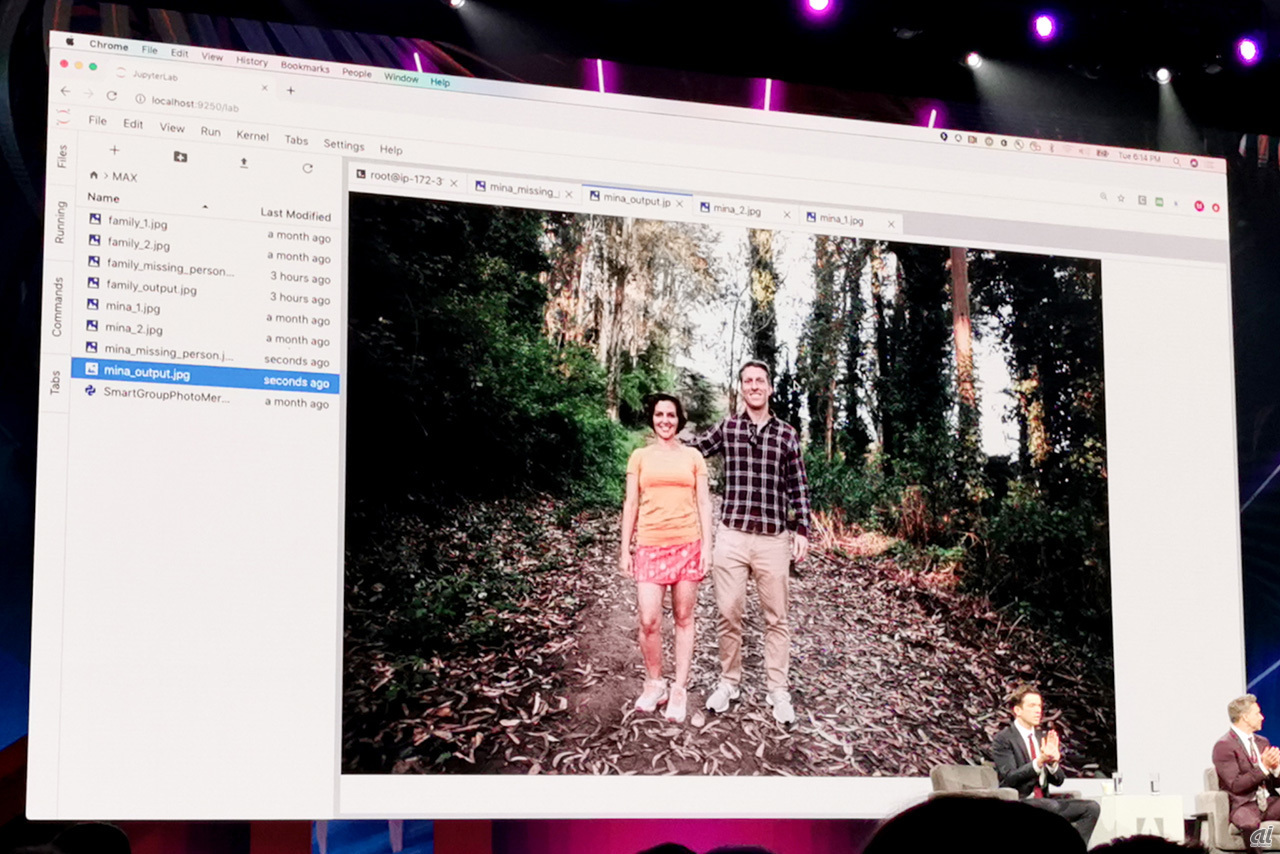
トップバッターは、別々に撮影した人物写真をあたかも一緒に撮影したかのように違和感なく合成できる「All In」という技術。Adobe Senseiを活用し、写真で合成したい人物を選択。被写体を自動で切り抜きして、もう一つの写真にうまく合成することができる。言及されていなかったものの、色味なども自動で調整してくれるように見えた。また、複数人の写真でも対応可能で、デモでは、父親+子どもの写真に母親をうまく合成させていた。

次に登場したのが、インタビューやPodcast配信時にありがちな「あー」とか「えっと」などを取り除ける技術で、不要な音を指定し、それと同じと思われる音をAdobe Senseiが検出して削除。スムーズな音声に変換できる。これは、言語や言葉に関わらず利用でき、車のクラクションをだけを取り除くデモも披露していた。
特定の言葉や特定のノイズ音を取り除くことができるSound Seek。フレーズを指定して解析すれば同じ音を発している箇所を自動的に選択してくれる。#AdobeMAX pic.twitter.com/E2Tl6eYzyE
— 山川晶之 (@msyamakawa) November 6, 2019
声に合わせたアニメーションを最も手軽に生み出せるのが「Project Sweet Talk」だ。既存のCharacter Animatorでは、キャラクターのパーツごとにレイヤーを用意する必要があるが、イラストの1枚と音声データのがあれば、数秒でアニメーションを生成することができる。デモでは、決してクオリティの高くない手描きイラストや絵画の人物でアニメーションを生成していた。
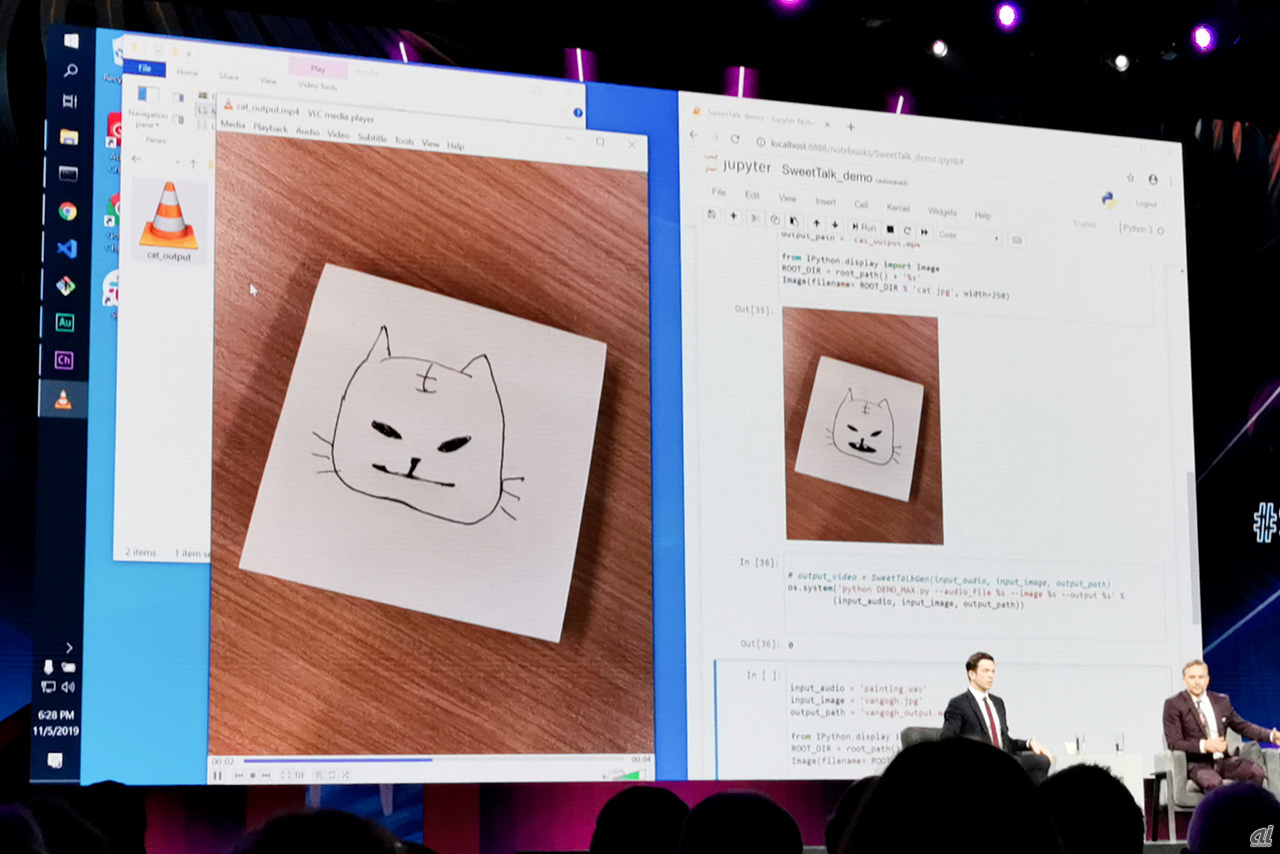
音声データをもとに、1枚の画像から数秒でアニメーションを作成できるProjectSweetTalk。#AdobeMAX #SWEETTALKSNEAK pic.twitter.com/DtolNgIA8y
— 山川晶之 (@msyamakawa) November 6, 2019
少し難解だったのが「Project Pronto」という3Dモデルを実写映像に違和感なく合成する「モーショントラック」を簡素化するものだ。同プロジェクトでは、スマートフォンで撮影した動画でモーショントラックを実現するもので、スマートフォンのセンサーをもとに3Dモデルを動画上に合成する。デモでは、机をタップしたり、3Dオブジェクトから何かを引っ張り出したりする動作を予め録画。そのタイミングに合わせて3Dモデルを動かすことで、ARコンテンツ風の動画を作成できる。開発者は、ARコンテンツのプロトタイプに便利だと説明していた。

簡単なイラスト、例えば手描きで書いた鳥やバッグが実際にあったどんな見た目になるのだろう……を叶えてくれるのが「Project Image Tango」だ。手書きのイラストと、そのイラストを実写化する際に参考となる画像を入力すると、手描きのイラストをベースに実写画像を生成することができる。デモでは、手描きの小鳥のイラストをもとに、実際には存在しない鳥の画像を生成。さらに、元素材は画像でもOK。一つのドレスから、さまざまなカラーで種類の違う衣服を入力すると、そのカラーに合わせたドレス画像が生成された。


CNET Japanの記事を毎朝メールでまとめ読み(無料)
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ
 プライバシーを守って空間を変える
プライバシーを守って空間を変える
ドコモビジネス×海外発スタートアップ
共創で生まれた“使える”人流解析とは

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた  「ストリートビュー」が捉えたクレイジーすぎる光景38連発
「ストリートビュー」が捉えたクレイジーすぎる光景38連発  絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法
絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法