日本マイクロソフトは6月21日、2020年に向けたインバウンド需要に対応する人工知能(AI)や機械学習(ML)による多言語コミュニケーションを実現するビッグデータ基盤の構築について、豊橋技術科学大学、ブロードバンドタワーと協業することを発表した。東京オリンピックに向けて、観光や医療、災害など各種情報をリアルタイムに提供する械翻訳サービスを「2020年を目標に、3者が得意分野を持ち寄って実現する」(豊橋技術科学大学 副学長 原邦彦氏)とする。

最初に登壇した原氏は、欧米では機械翻訳が実用レベルに達しつつあるのに比べて、日本語から他の言語への機械翻訳については精度が低いと現状を分析する。原氏は「日本語が持つ構造的な問題が障壁となる」と述べ、汎用的な機械翻訳ではなく、ヘルスケアやツーリズムなど分野を特化させることで、日本語からの英語への機械翻訳を実用レベルまで高めることが、豊橋技術科学大学がプロジェクトの主目的だと語った。
今回は豊橋技術科学大学とブロードバンドタワー、そして日本マイクロソフトの3者が協業してプロジェクトに取り組む。その3者の役割だが、日本マイクロソフトはAI&ML技術に加えて、膨大なデータの管理・活用のためにMicrosoft AzureとMicrosoft Translator APIを提供。豊橋技術科学大学はAI&ML分野における重要語句の抽出や、目的に応じたデータの分類などを行い、サービス利用者との協働基盤の構築を担う。ブロードバンドタワーは、IoT基盤となるサービス構築およびAI&MLを活用した事業構築を行う新会社「エーアイスクエア」を設立してビジネスへつなげる。

「現状もアルゴリズムを組んでデータ解析を行っているが、(旅行者が多様な場面で母国語による情報を必要とする)複雑な場面を想定するのは難しい」と日本マイクロソフト 執行役 CTO 榊原彰氏。同社はMicrosoft Researchが研究・開発した「Microsoft Cognitive Services」のAPI群を活用し、ASR(自動音声認識)から得た会話データをMicrosoft Translatorで分析し、機械翻訳クライアントを通じて機械翻訳の結果を提供している。ここを実ビジネスへつなげていくことが今回のプロジェクトの目的だ。
Microsoft Cognitive Services APIの1つであるMicrosoft Translator Text APIは、すでに50言語に対応し、複雑な日本語も正しく英語に翻訳できれば、その広がりは多岐にわたる。「翻訳字幕の自動化や、街中にキオスク端末を設置して道案内や土地の名産品を知るようなシナリオも考えられる」(榊原氏)
ブロードバンドタワー 代表取締役 会長兼社長 CEO 藤原洋氏は、「この20年間、日本のGDPが下がり続けている。従来型の製造業主体の構造では日本の将来は危うい」と語り、インバウンドがもたらす経済効果に注目する。




藤原氏の説明によれば、3人の旅行者が来日すると、その経済効果は小型自動車2台の輸出利益と同等。仮に6000万人の旅行者が日本を訪れれば、4000万台の小型自動車を輸出するのと同等の利益になるとする。「高度なAI技術が産業構造の転換につなげる」(藤原氏)と語り、まずはアプリケーションを作成し、インバウンド事業者や旅行代理店、ホテルなどにプラットフォームを提供していくとした。インバウンド旅行者を増やして、日本は便利な国であることを感じてもらいつつ、社会全体への刺激につなげたいと意気込む。
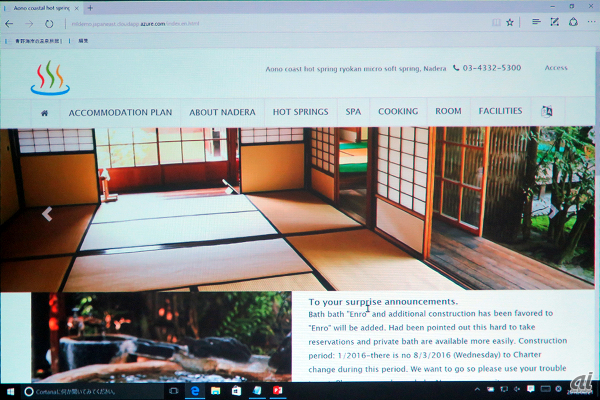
日本マイクロソフト 業務執行役員 ナショナルテクノロジーオフィサー 技術統括室 田丸健三郎氏は、日本の観光情報を海外に発信するためのテクノロジとして、ウェブサイトのリアルタイム翻訳デモンストレーションを行った。一般的にウェブページの多言語化は手間や費用がかかるもの。ここでバックエンドにMicrosoft Azure上の機械翻訳サービスを利用すれば、目の前で入力した文章を英語や中国語に自動翻訳できる。
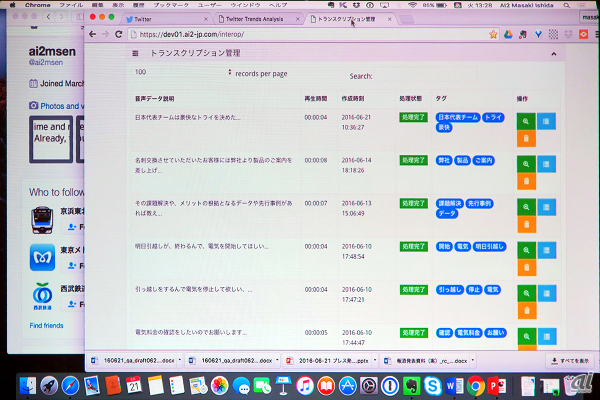
また、エーアイスクエア 代表取締役 石田正樹氏は、SNS情報の動向分析と多言語化発信を行うデモンストレーションを披露。独自のテキスト解析エンジンを使用し、数万のツイートから抽出して自動でタグ付けすることで、専門辞書への登録を可能にする。「テキストの文脈を理解するアルゴリズムは言語に依存しないため、英語などからも単語の抽出が可能」(石田氏)だと説明した。
本プロジェクトの核となるのが、豊橋技術科学大学 情報メディア基盤センター 教授の井佐原均氏の研究だ。日本語の語順を英語の語順に置き換えて、機械翻訳すると品質が向上する例を交えながら、「日本語は難しいながらも、考えて書けば翻訳精度は高まる。今回はツーリズムなど分野に応じた専門的な文章になるため内容は限定される。現状でも実用レベルに近づけられる」(井佐原氏)。1度、英語に翻訳してしまえば、MicrosoftのAPI群で他の言語に翻訳できるので可用性も高そうだ。プロジェクトの成果に対しても、「可能であれば一般公開し、他のソリューションでの活用も目指したい。できるだけ日本全体で使える枠組みを目指す」(井佐原氏)と語る。すでに宮崎県の観光協会に相談し、データの利用許諾を得ているそうだ。
機械翻訳はMicrosoftに限らず世界レベルで高度化し、その成果は多くの場面で目にするようになったが、「学習するための材料が重要」(田丸氏)だ。「海外は比較的オープンだが、日本はプライバシー問題などから材料を収集するのが難しい。だからこそ今回の3者連携の取り組みが、翻訳エンジンの精度向上につながる」(田丸氏)Microsoft Translatorエンジンは現在バージョン3だが、「年内のバージョンアップを目指す」(榊原氏)という。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた  絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法
絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法 .jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話