連載2回目は、ネット時代の要請を受けて、データマイニングを取り巻くツール環境がどのように変化(進化)をしているかを、ご紹介させていただきます。
現在、企業内のDWH(データウェアハウス≒巨大なDB)に蓄積された膨大なデータは、例えればダムに貯められた水です。ただ水門を開け閉めするだけでは、膨大な水量(データ量)が流出してしまい、現実的に意思決定の材料としては機能しません。まさに消防ホースから水を飲むようなもので、受け手の処理能力を軽く超えてしまうのです。そこで、処理が可能な適切な量・質に情報を絞り込んで取り出す「蛇口」が必要となり、その機能がデータマイニングに求められています。
しかし、現実問題として、そのマイニング自体が非常に高度で職人的な作業であるため、属人的な制約をうけることになります。つまり、分析者の能力と人数に限界があるため、結果として処理できる件数とデータ量にもすぐに限界が来てしまいます。
そこで、そのような問題をカバーするためにツールの進化が求められ、ようやく、これに応えるようなソフトウェアが出始めました。
まず、これまでのマイニング作業を理解いただくために、一般的なデータマイニング・ツールでの作業のイメージをご紹介します。
マイニングの作業プロセスは以下のように、大きく「データ加工」と「アルゴリズムの適応」と「結果の評価」という3プロセスで構成されます。
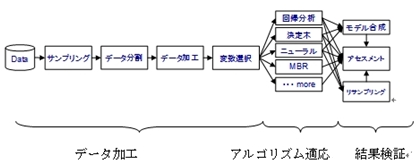
このプロセスを具体的に実際のマイニングツールで実施する際、下記の画面イメージのように、様々なノードをつないで、処理フローを構成することになります。
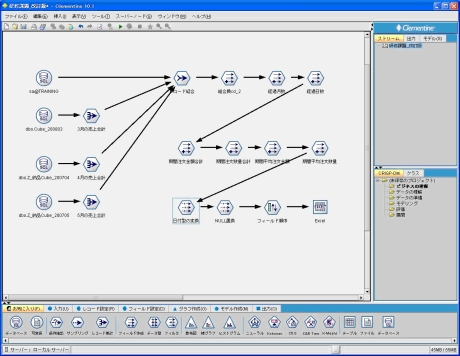
この処理フローを組む操作自体は、ドラッグ&ドロップで非常に簡単に行うことができますが、
というあらゆる操作ごとに判断作業が必要になり、その前提として統計やアルゴリズムの知識が求められます。
つまり、「操作は簡単」だけれども「分析は難しい」わけで、ツールの簡単さとは裏腹に、データマイニング業務は、知識と経験が豊富な分析官のみが行える専門性の高い労働集約的な作業で、時間が掛かり、当然にミスも発生します。分析内容にもよりますが、一般に安定した結果を得るために2〜3カ月程度を要します。
また、上述のように人の判断に依存するプロセスを数多く経るため、同じデータを使った分析でも、分析者の経験やスキルなどの能力で、大きく結果に差が出てしまうことになり、企業が安心して業務に活用する上で障害になっています。何より、作業のプロセスの多くがデータ加工部分で占められていることから分かるように、(時間の経過等で)データの内容が変わると、最初から作業を行う必要があるという問題が残ります。
このような問題の解決のため、第1回のコラムでもご紹介した
が求められており、これらに応える次世代のツールが登場しはじめています。その代表例が、KXEN社のKXEN Analytics Frameworkです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する
