

EduLabは1月18日、ディープラーニングに基づくAIを活用した手書き文字のテキストデータ化サービス「DEEP READ」の販売を開始した。料金は月額20万円からで、個別のカスタマイズなども可能。
EduLabグループは、前身の教育測定研究所の事業を含め、約15年前から100万人規模のテスト採点業務を受託し、膨大な答案を分析してきたという。2020年の大学入試センター試験から、マークシートのような選択式ではなく記述式の答案が増えることから、この採点にかかる時間や費用を減らせないかと考えたことが、DEEP READを開発するきっかけになったと、同社の事業開発室マネージャーである松本健成氏は話す。

従来型の「OCR(光学的文字認識)」技術では、活字は高い精度でデータ化が可能なものの、形にばらつきがある手書き文字の認識精度は低く、人力による打ち込み(パンチ入力)作業に頼ったデータ化が一般的だった。また、多くの企業・団体は、手書き文字の入力作業を海外などにBPO(外部委託)しており、膨大な時間的・費用的コストがかかっているという現状がある。
同社ではこの問題を解決するために、約1年半前からAI文字認識の研究開発を開始。殴り書きしたような汚い文字も含め、約3万5000点の手書き文字データを読み込ませることで、人力でデータ入力した際の精度である平均93%を上回る93.5%の精度を実現したという。また、特定の手書きの帳票の読み取りでは98.9%の精度を誇るという。最大200の複数文字を一度に認識可能だ。
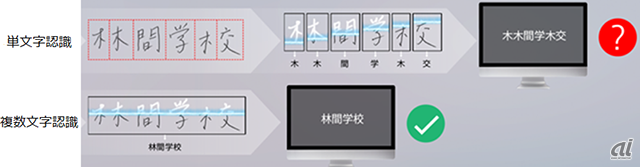
「当初は競合他社と同様に1文字ずつ認識をさせてみたが、手書き文字同士がつながっていたり、枠線などに掛かっているとうまくいかなかった。そこで方式を大きく変えて、1文字だけでなく前後のコンテキストも含めることで高精度での認識に成功した」と、同社事業開発本部執行役員の安永達矢氏は開発の苦労を語る。
たとえば、「ユミコ」という名前を汚く書くと、「ユ」と「コ」の文字が数字の「2」に見えてしまうことがある。従来のOCR技術ではこの違いを認識することが難しかったが、DEEP READによってこの3文字を一度に認識することで、ユミコと正確に判別できるという。

競合他社の中には、より高い精度をアピールする企業もあるが、そもそも手書き文字データのサンプル数が少なく実用性が低いものも少なくないと松本氏は指摘する。また、従来のOCRサービスは辞書データを活用していることが多く、辞書に登録されていないキーワードを認識できないこともあるそうだが、DEEP READはディープラーニングによって、どのような文字であっても認識できる点が強みだとした。
教育現場での活用イメージとしては、手書きの答案をAIでテキスト化して、採点システムに読み込むことで、特定のキーワードを含む・含まないといった内容によって答案を事前に分類。正解・不正解に関係なく、すべての回答を確認しなければいけなかった採点者の時間を大幅に削減できるようになるとしている。このほかにも、銀行や保険の申込書、医療の診断書など、“膨大な紙データ”を保有する幅広い業界で活用できると考えているという。
料金は、一般ユーザー向けのクラウド版の利用料が月額20万円で、1カ所のデータ化につき追加で0.5円が発生する。たとえば、3〜4人のアルバイトスタッフに毎日データ入力を依頼しており、人件費を抑えたい事業者などの利用を想定しているという。また、クラウドではなくオンプレミスを希望する企業や、社内システムと連携させたい企業などについては個別見積もりとなる。
今後は、手書き文字の認識が難しく、読み取り内容が不確かな箇所にフラグを立てる機能を実装する予定。また、現在はデータ化したい箇所の属性を事前に定型フォーマットとして設定する必要があるが、レシートや名刺など、フォーマットがその都度異なる書類でも認識できる技術を搭載する予定だという。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 プライバシーを守って空間を変える
プライバシーを守って空間を変える
ドコモビジネス×海外発スタートアップ
共創で生まれた“使える”人流解析とは
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす
 心と体をたった1分で見える化
心と体をたった1分で見える化
働くあなたの心身コンディションを見守る
最新スマートウオッチが整える日常へ

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

.jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話  絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法
絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法  なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは