今や、「検索」という言葉はテレビCMや雑誌、電車内広告に氾濫し、消費者の間に完全に浸透している。特に、ウェブ検索の入り口はPCから携帯電話やテレビにも広がり、検索対象のほうもConsumer Generated Media(CGM)を中心に急速に拡大している。
こうした流れの中で、1999年から開催されている「NTCIR(エンティサイル)」というワークショップをご存じだろうか。NTCIRは情報検索技術の国際ワークショップで、情報アクセス(膨大な情報に埋もれた有用な情報をユーザーに提供するための技術の総称で、情報検索を包含する)の研究に従事する世界中の研究者が一斉に共通の研究課題に取り組み、競争と協調を通して技術進歩を促進する「情報検索のオリンピック」である。
NTCIRに参加するのは、情報過多の世の中をより暮らしやすくするための基礎技術を手がけている企業や大学の研究者たちだ。約1年半に1度のペースで開催されており、直近では5月15日から18日の間、第6回目となる会議が東京の国立情報学研究所にて行われた。
主な検索対象はアジア言語のテキストだが、今回は欧米も含め12カ国から参加があった。正式種目としては、
――が設けられた。各種目の結果はNTCIRのサイトに公開されている。下のスライドにあるように、最近のNTCIRの参加チーム数は100に届きそうな勢いである。
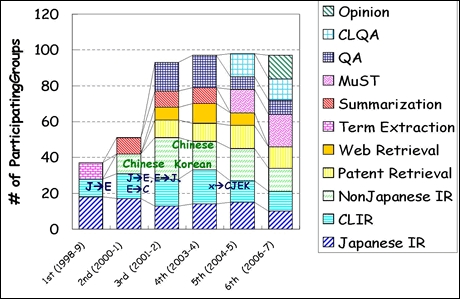 第1〜6回NTCIRの種目別参加チーム数の推移
第1〜6回NTCIRの種目別参加チーム数の推移これまで開催された種目はOPINON(意見分析)、CLQA(言語横断質問応答)、QA(質問応答)、MuST(動向要約)、Summarization(要約)、Term Extraction(用語抽出)、Web Retrieval(ウェブページ検索)、Patent Retrieval(特許検索)、Non-Japanese IR(日本語以外の検索)、CLIR(言語横断検索)、Japanese IR(日本語検索)。なおNTCIRでは最後の3つが言語横断検索の種目に含まれる。
つい最近、Googleが自動翻訳による言語横断検索サービスを公開するというニュースが流れたが、言語横断検索の研究は10年以上前から盛んに行われており、NTCIRにおいても第1回NTCIRから毎年メイン種目として取り組まれてきた。今年は世界から22チーム――日本企業では東芝/ニューズウォッチ、ヤフー、ジャストシステム、大学では米国のUC Berkeley、City University of New York、スイスのNeuchatel大学、その他シンガポールのInstitute for Infocomm Researchなどが参加している。
他の種目には言語横断検索ほど多くの参加はないが、例えば質問応答は、ユーザーに検索結果の文書全体を読ませる代わりに必要な情報だけ抜き出して提示するため、用途によっては文書検索より有用である。特許の資料調査や分類も、特許審査官や会社の知財部門に直接役立つ研究である。また、今回新設された意見分析は、ブログなどの玉石混淆(というより大半が石)のCGMから有用情報を抽出するために、おそらく数年以内に実社会で役立つであろう。一方、古典的な文書検索は、対話型質問応答や意見分析などの高度な種目の1要素技術という位置づけで研究が継続されるであろう。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 ひとごとではない生成AIの衝撃
ひとごとではない生成AIの衝撃
Copilot + PCならではのAI機能にくわえ
HP独自のAI機能がPCに変革をもたらす
 プライバシーを守って空間を変える
プライバシーを守って空間を変える
ドコモビジネス×海外発スタートアップ
共創で生まれた“使える”人流解析とは

 【独占】生成AI勃興でリストラ敢行 巨額調達ダイニーが人材削減に踏み切った理由
【独占】生成AI勃興でリストラ敢行 巨額調達ダイニーが人材削減に踏み切った理由
 【独占】みずほFG傘下の道を選んだUPSIDER宮城社長インタビュー 「スイングバイIPO当然目指す」
【独占】みずほFG傘下の道を選んだUPSIDER宮城社長インタビュー 「スイングバイIPO当然目指す」
 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは  AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は .jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話