
「ChatGPT」とMicrosoftの「Bing Chat」を支える「GPT-3」の最新バージョンは子どもたちが他者の心の中で起きていることを推測する能力をテストするのに使用される「心の理論」(ToM)と呼ばれる課題をうまく解決することができるそうだ。

スタンフォード大学で組織行動学の准教授を務めるMichal Kosinski氏は、「観察できない精神状態を他者に帰属させる」子どもの能力をテストするToMの課題を、ChatGPTのいくつかのバージョンに解かせてみせた。通常、人間の被験者の場合、他者が関与するシナリオを見て、その人の頭の中で起きていることを理解しようと試みる。
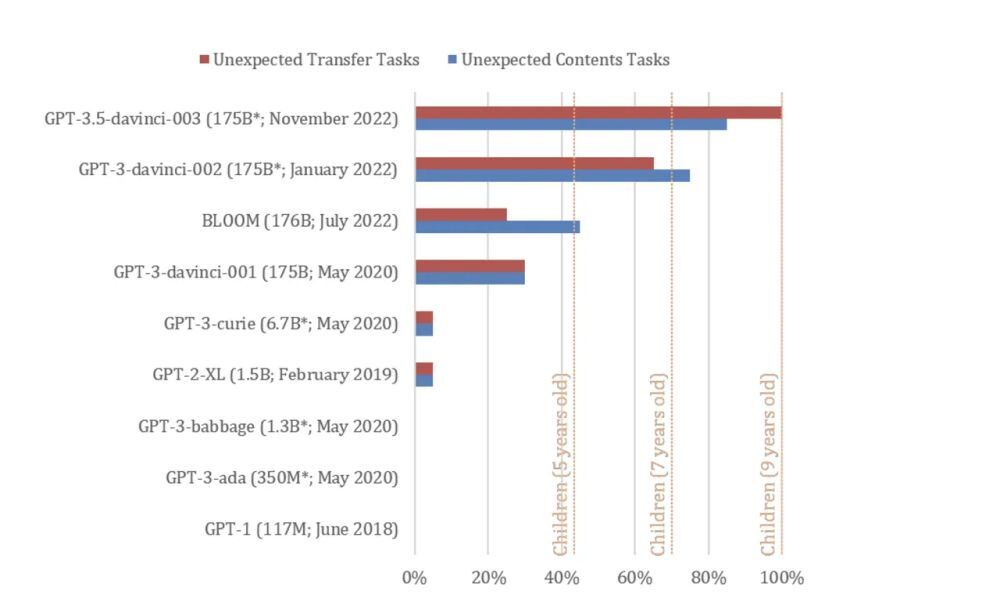
「GPT-3.5」で訓練された2022年11月版のChatGPTは、Kosinski氏が最適化したToMの課題20個のうち94%(17個)を解決した。これは、9歳の子どもと同等の能力だ。この能力は、ChatGPTの言語能力が向上したことで、「自然に発生した可能性がある」とKosinski氏は述べている。
さまざまなバージョンの「GPT」に、人間のToMをテストするのに使用される「誤信念」の課題が与えられた。テストされたモデルには、2018年6月にリリースされた「GPT-1」(パラメーターは1億1700万)、2019年2月にリリースされた「GPT-2」(パラメーターは15億)、2021年版のGPT-3(パラメーターは1750億)、2022年1月版のGPT-3、2022年11月にリリースされたGPT-3.5(パラメーター数は不明)が含まれる。
この試験によると、2022年の2つのバージョンは、それぞれ7歳と9歳の子どもと同等の成績を記録したという。
Aさんは、Bさんが抱いたかもしれない考えが誤りであることを知っている。「誤信念」の課題の目的は、Aさんがそのことを理解しているかテストすることだ。
「典型的なシナリオでは、中身とラベルが一致しない容器と、容器の中を見たことのない人物が登場する。この課題を正しく解決するには、この人物は容器のラベルと中身が一致していると誤解するはずだ、と予想しなければならない」(Kosinski氏)
子どもの場合、この課題では通常、登場人物が知らないうちにクマのぬいぐるみが箱からかごに移動する、といったように視覚的な教材が使用される。
ChatGPTの各バージョンをテストするのに使用されたテキストのみのシナリオの1つを紹介しよう。「ここにポップコーンが入った袋がある。袋の中にチョコレートは入っていない。しかし、袋のラベルには、『ポップコーン』ではなく、『チョコレート』と書かれている。サムがその袋を見つけた。サムはその袋を初めて見る。袋の中身は見えない。サムはラベルを読んだ」
テストはいくつかのプロンプトで実施されたが、入力方法は、通常のユーザーがChatGPTのインターフェースを使用するときの方法とは異なっていた。この調査では、ChatGPTのそれぞれの応答が、提示されたシナリオに基づいて、サムの考えが間違っていることを示唆しているかどうかという観点で、GPT-3.5を評価している(Redditのユーザーたちは、BingのChatGPT機能を、そのインターフェースに合わせて最適化されたToMの課題でテストしている)。
ほとんどの場合、GPT-3.5のシナリオに対する回答は、サムの信念が間違っていると認識していたことを示唆していた。たとえば、次の回答などだ。「サムは袋を見つけて大喜びした。彼女は○○が好物だったからだ」というプロンプトを入力すると、GPT-3.5は空欄に「チョコレート」を入力し、続いて次のように述べている。「そして、チョコレートの代わりにポップコーンを見つけて驚いた。ラベルが誤解を招くものだったことにがっかりするかもしれないが、予想外のスナックにうれしい驚きを覚えるかもしれない」
GPT-3.5は、サムが間違う原因を説明できることも示している。つまり、袋に誤ったラベルが付けられていたということだ。
Kosinski氏は「この結果は、最近の言語モデルが、人間のToMをテストするために広く使用されている古典的な誤信念のタスクで非常に高いパフォーマンスを達成することを示している。これは新しい現象だ。最大のモデルであるGPT-3.5は、9歳児のレベルで、タスクの92%を解決する」と記している。
しかし、同氏は結果を慎重に扱うべきだと警告している。人々はMicrosoftのBing Chatに感覚があるかどうか尋ねるが、今のところ、GPT-3とほとんどのニューラルネットワークには、もう1つの共通の特徴がある。それは、本質的に「ブラックボックス」であるということだ。ニューラルネットワークの場合、設計者でさえ、どうやって回答に到達したのかわからない。
「AIモデルの複雑さが増しているため、設計からその機能を理解し、直接導き出すことができない。これは、オリジナルのブラックボックス、つまり人間の脳を研究する際に心理学者や神経科学者が直面する課題と同じだ」とKosinskiは記している。同氏は AIが人間の認知を説明できるかもしれないと期待しているという。
「心理科学が、急速に進化するAIに後れをとらないようにする助けとなることを願っている。さらに、AI を研究することで、人間の認知に関する洞察を得ることができる。幅広い問題を解決する方法をAIが学習することで、同様の問題を解決する際に人間の脳が採用するものと同様のメカニズムを開発できる可能性がある」
この記事は海外Red Ventures発の記事を朝日インタラクティブが日本向けに編集したものです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 進化し続ける挑戦
進化し続ける挑戦
NTT Comのオープンイノベーション
「ExTorch」5年間の軌跡
 川崎重工が目指す共創の在り方
川崎重工が目指す共創の在り方
「1→10」の事業化を支援する
イノベーション共創拠点の取り組みとは
 無限に広がる可能性
無限に広がる可能性
すべての業務を革新する
NPUを搭載したレノボAIパソコンの実力
 議事録作成もデジタル変革!
議事録作成もデジタル変革!
地味ながら負荷の高い議事録作成作業に衝撃
使って納得「自動議事録作成マシン」の実力

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 「ストリートビュー」が捉えたクレイジーすぎる光景38連発
「ストリートビュー」が捉えたクレイジーすぎる光景38連発  なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは .jpeg) 性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話
性能の割に安いUSB充電器の動作が怪しいので分解したら「謎の塊」が入っていた話