NTTは5月30日、クルマから見える移り変わる景色を話題に、パートナーのように知識、共感などを応答する対話AIを開発したと発表した。

NTTは、人の日々の“コミュニケーションパートナーAI”の実現を目指し、対話を通して人の興味や思考を引き出したり人の対話欲求を充足したりする、雑談対話AIの開発に取り組んでいる。近年の深層学習技術の進展によって、対話AIの性能は急激に向上しており、同社でも日本語最大規模の学習データを用いた高性能日本語対話AIを構築しているという。
一方、従来の対話AIの課題として、入力できる情報がテキスト情報のみに限られる点があると指摘。日々のコミュニケーションパートナーを目指す上では、身の回りの実際の状況を理解し、対話に取り込むことが求められる。そこで同社は、クルマなどの移動体から見える移り変わる景色を話題として、パートナーのように知識応答や共感応答をする対話AIを開発。常に自己位置が変化する状況下で、自己の周囲の景色やそこにひも付いた情報に基づいて雑談対話を行う対話AIを世界で初めて実現したとしている。
具体的には、超大規模ウェブ対話データ、高品質対話データと、深層学習技術(Transformer Encoder-decoderモデル)を組み合わせることで、日本語最大規模の対話モデルを構築。ルールや係り受け関係などの統計情報に基づく従来のモデルに比べ、抜本的に異なるレベルで複雑な文脈の理解や自然な発話の生成を実現できる。雑談AIの性能を競う「対話システムライブコンペティション3」でも、圧倒的な成績で優勝するなどの成果を挙げているという。
なお、対話モデルや対話データは、検証、評価目的に限定して無償公開。幅広いフィールドで構築したモデルの効率的な検証を進めている。
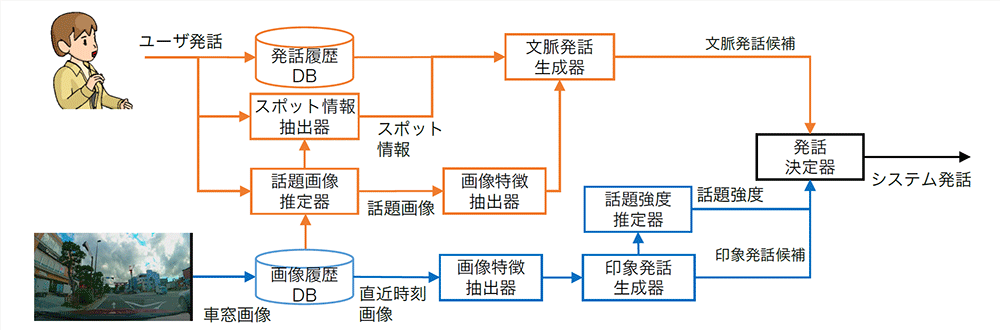
また、NTTによると、従来の大規模対話モデルはテキストのみを入力情報として扱うため、テキストに閉じた対話では自然に雑談できるものの、周辺の状況に即した対話を行うことは困難だという。人とドライブを楽しむ対話AIを実現するには、自己位置周辺の景色画像や外部のスポット情報を適切に処理しながら、対話に反映させる必要があると指摘している。
NTTはこうした課題に対し、画像内の物体の情報と自己位置周辺のスポット情報を大規模対話モデルに導入する技術を開発。
画像内に写っている物体群は、物体検出と呼ばれる技術で抜き出し、それぞれを大規模対話モデルで扱える数値情報(埋め込みベクトル)に変換して入力。スポット情報は、自己位置近傍のレストランなどのスポットに関する情報(ジャンル、名称など)をテキスト形式で取り出し、対話の文脈と同様の形式で入力するという。
これらの入力情報を大規模対話モデルに反映、対話AIの発話を出力。また、このように設計したモデルをドライブ対話データ(運転画像を見ながらガイド役とドライバー役の間で行った対話)で学習することで、自己位置周辺の景色画像、スポット情報に基づく発話生成を実現したという。
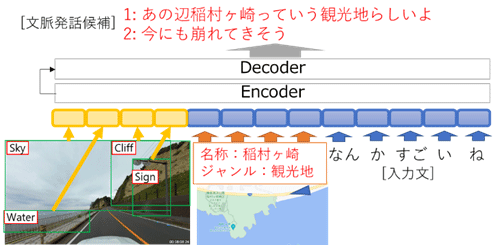
なお、ドライブ中の自己位置は逐次的、連続的に変化する。対話AIでは、人がどの時点の画像やスポット情報を話題としているのかを理解しつつ、新規に入力された情報にも適切なタイミングで触れながら対話する必要がある。
今回、対話文脈からの話題画像推定と、逐次的に入力された画像に対する発話の話題強度の推定技術を開発し、それらを適切にタイミング制御に組み込むことで、これらの課題を解決。これにより、利用者の発話に自然に応じながら、強く興味を惹かれるであろう情報を適切なタイミングで提供する、新感覚のドライビングパートナーとなる対話AIを実現しているという。
今後は、日常的なドライブのパートナーを目指し、日々繰り返される対話への適用や、外部知識のさらなる利用に取り組む。また、長距離運転時の居眠り運転、漫然運転の防止や、自由な会話で検索可能な音声ナビゲータの実現を目指し、実車、VRなどでの実証実験を進めていくとしている。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 川崎重工が目指す共創の在り方
川崎重工が目指す共創の在り方
「1→10」の事業化を支援する
イノベーション共創拠点の取り組みとは
 議事録作成もデジタル変革!
議事録作成もデジタル変革!
地味ながら負荷の高い議事録作成作業に衝撃
使って納得「自動議事録作成マシン」の実力
 進化し続ける挑戦
進化し続ける挑戦
NTT Comのオープンイノベーション
「ExTorch」5年間の軌跡
 無限に広がる可能性
無限に広がる可能性
すべての業務を革新する
NPUを搭載したレノボAIパソコンの実力

 メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
メルカリが「2四半期連続のMAU減少」を恐れない理由--日本事業責任者が語る【インタビュー】
 なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
 AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
AIが通訳するから英語学習は今後「オワコン」?--スピークバディCEOの見方は
 パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
パラマウントベッド、100人の若手が浮き彫りにした課題からCVCが誕生
 野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
野村不動産グループが浜松町に本社を「移転する前」に実施した「トライアルオフィス」とは
 「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
「ChatGPT Search」の衝撃--Chromeの検索窓がデフォルトで「ChatGPT」に
 「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
「S.RIDE」が目指す「タクシーが捕まる世界」--タクシー配車のエスライド、ビジネス向け好調
 物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
物流の現場でデータドリブンな文化を創る--「2024年問題」に向け、大和物流が挑む効率化とは
 「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
「ビットコイン」に資産性はあるのか--積立サービスを始めたメルカリ、担当CEOに聞いた
 培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
培養肉の課題は多大なコスト--うなぎ開発のForsea Foodsに聞く商品化までの道のり
 過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
過去の歴史から学ぶ持続可能な事業とは--陽と人と日本郵政グループ、農業と物流の課題解決へ
 通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
通信品質対策にHAPS、銀行にdポイント--6月就任のNTTドコモ新社長、前田氏に聞く
 「代理店でもコンサルでもない」I&COが企業の課題を解決する
「代理店でもコンサルでもない」I&COが企業の課題を解決する

 「ストリートビュー」が捉えたクレイジーすぎる光景38連発
「ストリートビュー」が捉えたクレイジーすぎる光景38連発  なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは
なぜPayPayは他のスマホ決済を圧倒できたのか--「やり方はADSLの時と同じ」とは  絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法
絶対に迷わずにiPhoneの電源を切る(シャットダウンする)方法