1と0の区別は得意だが家と木の識別は苦手なコンピュータにとって、画像処理は難しい問題である。人間にとっては簡単なこの作業を、多くのコンピュータは今でも上手く処理できないのだ。
従って、Googleや他社の画像処理ソフトウェアはこれまで、画像に付随するキャプションやタイトルなどのテキスト、つまり「メタデータ」に過度に依存してきた。ただし、GoogleはPicasa Web Albumsで顔認識技術を採用するなど、より高度な画像処理に取り組んでいる。
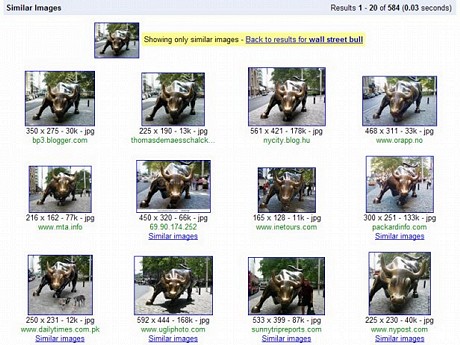
Googleは米国時間4月20日、同社がウェブ上で見つけた画像群の中から類似した画像を検知する技術を披露した。Googleのエンジニアリング担当部長で、画像検索プロジェクトの責任者を務めるRadhika Malpani氏によると、この技術は2つの画像の「視覚的な距離」を割り出して、画像データベースの中からその値が最も近い画像を見つけ出すという。
この技術は、言葉で表現することが難しい視覚的概念、例えば、「ピラミッドが前景にあるルーブル美術館」や「ブラッド・ピットが左側にいるときのブラッド・ピットとアンジェリーナ・ジョリー」などの画像を素早く見つけたいときに便利だ。
この記事は海外CNET Networks発のニュースをシーネットネットワークスジャパン編集部が日本向けに編集したものです。海外CNET Networksの記事へ
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 誰でも、かんたん3D空間作成
誰でも、かんたん3D空間作成
企業や自治体、教育機関で再び注目を集める
身近なメタバース活用を実現する
 ビジネスの推進には必須!
ビジネスの推進には必須!
ZDNET×マイクロソフトが贈る特別企画
今、必要な戦略的セキュリティとガバナンス
 データ統合のススメ
データ統合のススメ
OMO戦略や小売DXの実現へ
顧客満足度を高めるデータ活用5つの打ち手
 CES2024で示した未来
CES2024で示した未来
ものづくりの革新と社会課題の解決
ニコンが描く「人と機械が共創する社会」


 テレビを持たない若者たち--新たな体験で変化の兆しも
テレビを持たない若者たち--新たな体験で変化の兆しも .jpeg) 存在しないはずの「ターミナル0」が羽田に出現、なぜ?--異業種連携で「未来の空港」を研究開発へ
存在しないはずの「ターミナル0」が羽田に出現、なぜ?--異業種連携で「未来の空港」を研究開発へ  シャオミ初のEV「SU7」、MWCに登場
シャオミ初のEV「SU7」、MWCに登場