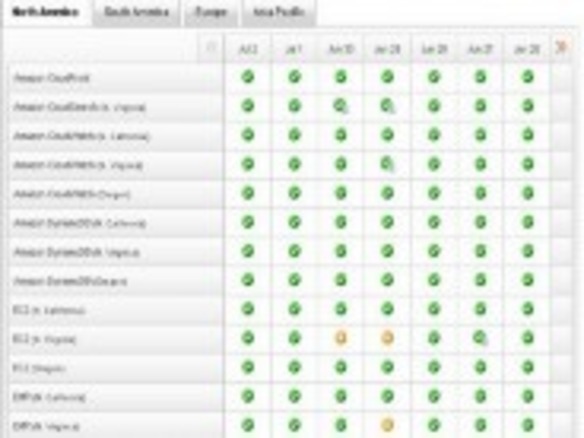
Amazonによると、米国時間6月29日の夜遅くからその週末にかけてAmazon Web Service(AWS)で発生した障害は落雷によって引き起こされたものの、同社のインフラに潜んでいたソフトウェアのバグのせいで回復までに時間がかかる結果となったという。
Amazonの障害分析レポートで明かされたバグの内容から、クラウドプロバイダが運用するシステムの規模というものがソフトウェアシステムの障害時にどれほど重大な影響を与えるのかが分かる。そして、こういったバグはGoogleの「規模が大きくなると問題があらゆる箇所に及ぶ」という言葉の正しさを証明する実例ともなっている。
Amazonによると、米国東部リージョンにおける同社のクラウド(4つのアベイラビリティゾーンにまたがる10カ所のデータセンターから成る)では最初、雷雨が原因と思われる外部電力の変動によって障害が引き起こされたという。
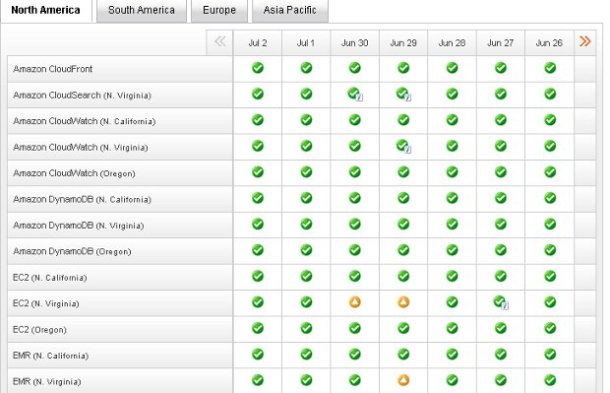
この障害によって、Elastic Compute Cloud(EC2)といったAWSの主要なサービスが停止することになった。しかし、サービスの停止が長引いた原因は、同社のソフトウェアに潜んでいた複数のバグにあったという。例を挙げると、あるデータセンターではバックアップ電源への切り替えに失敗し、最終的に無停電電源装置(UPS)のバッテリを使い切った結果、同リージョンのハードウェアがシャットダウンすることになったという。
Amazonによると、サービスのインスタンスが利用できなくなったことで「多くの顧客に重大な影響が及んだ」ものの、制御プレーン(顧客がリージョンの垣根を越えてリソースの生成や削除、変更を行えるようにするソフトウェア)の機能低下によってさらに事態が悪化したという。こういった柔軟性の喪失により、障害に対応しようとする顧客に足かせがはめられたというわけだ。
そして、問題はこれだけで終わらなかった。Amazonのサーバ起動プロセスにボトルネックが発生したため、EC2やElastic Block Store(EBS)といった主要なAWSコンポーネントのオンライン復旧に想定以上の時間がかかった。これにより事態はさらに悪化した。EBSが復旧した時点でさまざまな技術的なチェックを実施し、保存されているデータに影響が及んでいないことを確認する必要があるものの、影響を受けたハードウェアの数があまりにも多かったためである。その結果、「バックログの解消に数時間を要する」ことになった。
まとめると、こういった問題が重なり合ったため、非常用電源を稼働させるだけで終わっていた本来の場合に比べると、復旧プロセスが長引いたことになる。
この記事は海外CBS Interactive発の記事を朝日インタラクティブが日本向けに編集したものです。
CNET Japanの記事を毎朝メールでまとめ読み(無料)
 ビジネスの推進には必須!
ビジネスの推進には必須!
ZDNET×マイクロソフトが贈る特別企画
今、必要な戦略的セキュリティとガバナンス
 CES2024で示した未来
CES2024で示した未来
ものづくりの革新と社会課題の解決
ニコンが描く「人と機械が共創する社会」
 誰でも、かんたん3D空間作成
誰でも、かんたん3D空間作成
企業や自治体、教育機関で再び注目を集める
身近なメタバース活用を実現する
 脱炭素のために”家”ができること
脱炭素のために”家”ができること
パナソニックのV2H蓄電システムで創る
エコなのに快適な未来の住宅環境


.jpeg) 存在しないはずの「ターミナル0」が羽田に出現、なぜ?--異業種連携で「未来の空港」を研究開発へ
存在しないはずの「ターミナル0」が羽田に出現、なぜ?--異業種連携で「未来の空港」を研究開発へ  レトロかわいいAIデバイス「rabbit r1」を体験--新たなトレンドを作れるか?
レトロかわいいAIデバイス「rabbit r1」を体験--新たなトレンドを作れるか?  「Android」スマホのホーム画面を手軽に効率化する5つの方法
「Android」スマホのホーム画面を手軽に効率化する5つの方法