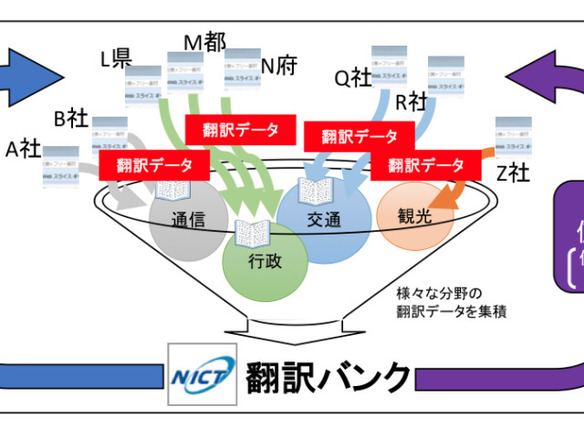
総務省とNICTは9月8日、自動翻訳システムのさまざま分野への対応や高精度化を進めるため、オール・ジャパン体制で翻訳データを集積する「翻訳バンク」の運用を開始すると発表した。
総務省とNICTは、世界の「言葉の壁」をなくすことを目指すグローバルコミュニケーション計画を推進している。その一環として、NICTは音声翻訳(VoiceTra)とテキスト翻訳(TexTra)の研究・開発・社会実装を進めている。
これまでNICTにおいては翻訳の高精度化に必要な翻訳データの集積に取り組むとともに、6月からニューラル機械翻訳技術の導入等を進めているが、翻訳技術を活用する分野によっては翻訳データが足りないことが課題となっていた。
そこで、総務省とNICTは、様々な分野における翻訳データの集積に向けて、NICTがさまざまな分野の翻訳データを集積して活用する「翻訳バンク」の運用を開始することにしたという。翻訳バンクの当面の目標として、100万文×100社=1億文の翻訳データの集積を目指す。

翻訳バンクの開始にあたっては、データを提供する側のメリットを明確化するため、NICTの自動翻訳技術の使用ライセンス料の算定の際に、提供が見込まれる翻訳データを勘案して負担を軽減する仕組みを用意したという。
高精度翻訳を実現することで「言葉の壁」をなくし、日本の経済・社会の活性化に貢献したいとしている。
プレスリリース | 『翻訳バンク』の運用開始CNET Japanの記事を毎朝メールでまとめ読み(無料)
 ビジネスの推進には必須!
ビジネスの推進には必須!
ZDNET×マイクロソフトが贈る特別企画
今、必要な戦略的セキュリティとガバナンス
 誰でも、かんたん3D空間作成
誰でも、かんたん3D空間作成
企業や自治体、教育機関で再び注目を集める
身近なメタバース活用を実現する
 CES2024で示した未来
CES2024で示した未来
ものづくりの革新と社会課題の解決
ニコンが描く「人と機械が共創する社会」
 データ統合のススメ
データ統合のススメ
OMO戦略や小売DXの実現へ
顧客満足度を高めるデータ活用5つの打ち手


 「ストリートビュー」が捉えたクレイジーすぎる光景38連発
「ストリートビュー」が捉えたクレイジーすぎる光景38連発  テレビを持たない若者たち--新たな体験で変化の兆しも
テレビを持たない若者たち--新たな体験で変化の兆しも  「Android」スマホのホーム画面を手軽に効率化する5つの方法
「Android」スマホのホーム画面を手軽に効率化する5つの方法